


Ever since I started reading science fiction as a bright-eyed and bushy-tailed young lad, I was exposed to the concept of robots that could “think” in that they could perceive the world around them and respond accordingly.
I was particularly impressed by the robots in Isaac Asimov’s stories in books like I Robot, The Rest of the Robots, The Caves of Steel, and The Naked Sun. As I’ve mentioned before, prior to Asimov, most robot stories were of the Frankenstein’s monster variety, along the lines of “Man creates creature, then creature runs amok and gives man a bad hair day.”
As an aside, talking about bad hair days, in my youth I flaunted a full head of flowing locks, never dreaming that I would one day end up in my current sorrowful state sporting what we might charitably refer to as a “reverse Mohican.” But we digress…
Suffice it to say that, once Asimov had codified his Three Laws of Robotics, the majority of robot-centric tales became much more nuanced.
I was just thinking back to when I was first exposed to the concept of real-world artificial intelligence (AI) and machine learning (ML) in the 1990s. One flavor of these were so-called “expert systems.” These systems took a lot of work to implement, and they really weren’t all that good. Another problem was that rascally marketeers quickly adopted the AI moniker and stamped “AI Inside” on everything they could lay their sticky hands on.
Much the same thing is happening today, with proclamations of “Gluten-Free” being associated with products that never contained any gluten in the first place. The result was that, by the end of the 1990s, the term “AI” had left a bad taste in everyone’s mouths (by some strange quirk of fate, the same can be said for the majority of today’s gluten-free products).
AI continued to be primarily of academic interest only until the mid-2010s. Gartner is a well-known and well-respected technological research and consulting firm, and one of the things for which they are well-known are their Gartner Hype Cycles.
Of interest to us here is the fact that the 2014 version of the Gartner Hype Cycle didn’t mention AI or ML at all. Just one year later, the 2015 Hype Cycle showed ML as having already crested the Peak of Inflated Expectations.
Now, of course, AI is all around us. For example, one application that is getting a lot of attention these days is the uninspiringly named ChatGPT, which is short for Chat Generative Pre-trained Transformer. As I wrote in my Using ChatGPT to Write a BASIC Interpreter blog, my friend Joe Farr posed the question, “Could you write a program in C# that acts as a BASIC interpreter?” Joe went on to say, “And it proceeded to give me a complete C# program listing. Not a fragment or snippet, but a complete bloody program listing along with an example of it working. You can see the darn thing typing out the code in front of your eyes… in real-time. It’s really frightening to watch.”
Of course, super-sophisticated AI applications like ChatGPT run in the cloud on humongous clusters of servers. There’s currently a trend to perform AI and ML at the Edge, which is where the internet meets the real world. Some low-end Edge AI can be performed on traditional microcontroller units (MCUs). Mid-range Edge AI may require MCUs augmented with neural processing units (NPUs). And high-end Edge AI may require special system-on-chip (SoC) devices boasting dedicated AI/ML accelerators.
Speaking of special SoCs, in my column How to Build a Multi-Billion-Transistor SoC, we introduced the MLSoC from the guys and gals at SiMa.ai, whose goal it is to provide effortless machine learning at the Embedded Edge. Created at the 16nm technology node, the entire MLSoC comprises billions of transistors. The “secret sauce” to all of this is their machine learning accelerator (MLA), which provides 50 trillion operations per second (TOPS) while consuming a miniscule 5 watts of power.
As part of that column, we discussed the various ways in which the IP blocks used to implement an SoC can be connected to each other. The predominant interconnect technology used in the 1990s was the bus. By the early 2000s, many SoCs were sporting crossbar switch-based interconnect. Now, in the early 2020s, SoCs are flaunting network-on-chip (NoC)-based interconnect.
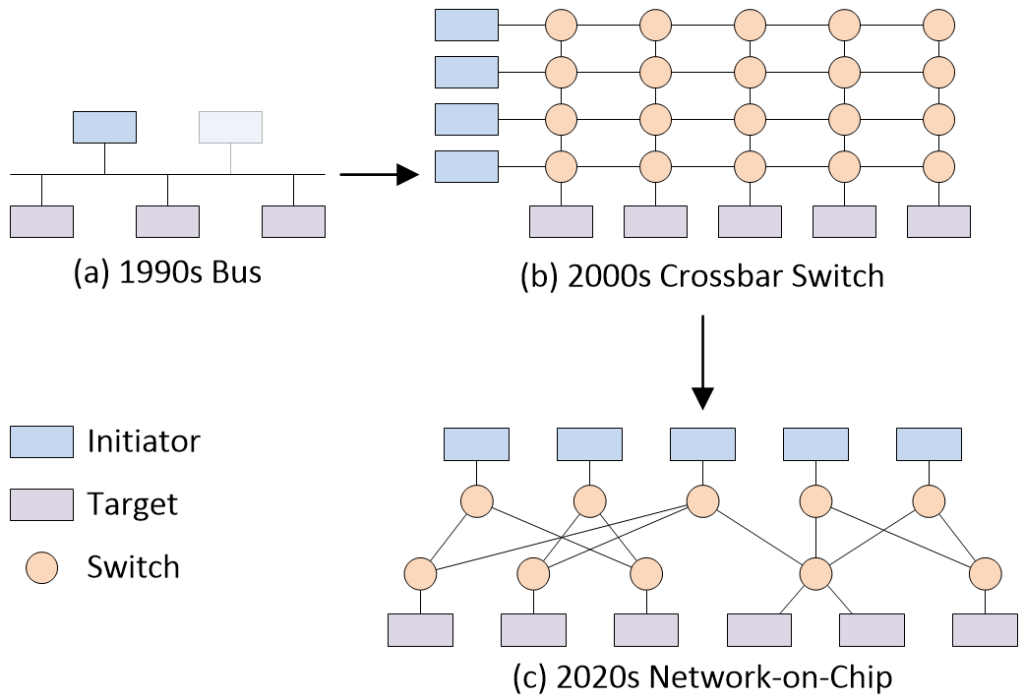
Different SoC interconnect strategies (Source: Max Maxfield)
Before we proceed, should we write “a NoC” or “an NoC”? In fact, both are correct depending on how one says “NoC” when speaking or “sounds it out” when reading. If you spell NoC out as “N-o-C,” then “an NoC” is the way to go. However, if you say “NoC” to rhyme with “sock,” then “a NoC” is the appropriate form (this latter approach is the way I think of things).
We are used to thinking of IP as occupying square or rectangular areas on the surface of the silicon chip. It takes a little thought to wrap your brain around the fact that a NoC is also a form of IP but, in this case, it’s IP that spans the entire chip.
If you are part of a team designing a new SoC, you could—of course—design your own NoC, but why would you? Creating a NoC from the ground up might require say six engineers working for around two years. Wouldn’t you rather have those engineers working on your secret sauce IP?
I’m reminded of the book How to Sharpen Pencils: A Practical and Theoretical Treatise on the Artisanal Craft of Pencil Sharpening for Writers, Artists, Contractors, Flange Turners, Anglesmiths, and Civil Servants by David Rees. There’s a quote on the back cover by Elizabeth Gilbert, who says: “Could I sharpen my own pencils? Sure I could! I could also perform my own dentistry, cobble my own shoes and smith my own tin—but why not leave such matters to real artisans, instead? I trust my bespoke pencils only to David Rees.” High praise indeed. I only wish I could afford to have my own pencils sharpened by a craftsman of David’s stature.
When it comes to NoCs, the defacto industry standards are the non-coherent FlexNoC and the cache-coherent Ncore interconnect IP from Arteris IP.
Who needs a NoC? To be honest, the way things are going, I’d say just about everyone designing a new SoC needs to be using one of these little scamps. I’m sure you’ve seen representations of different aspects of microprocessor trend data as illustrated in the image below.
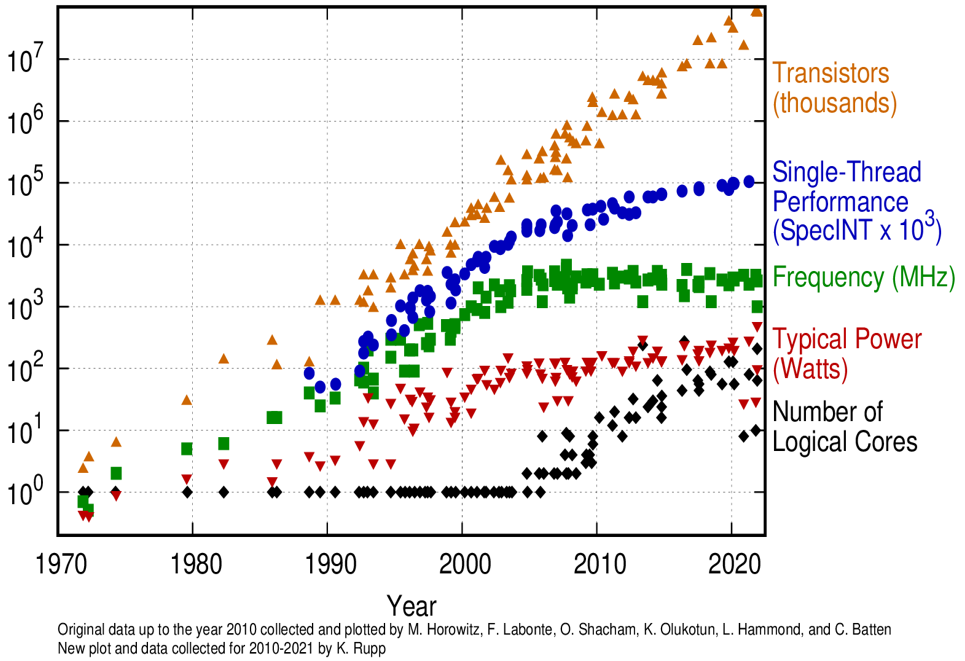
50 years of microprocessor trend data.
Observe that, although some aspects of this chart trail off over time, the number of transistors continues to grow exponentially (remember that the vertical axis is plotted using a logarithmic scale). The point is that trend data for SoCs is very similar, and it seems to me that the only way to manage designs of this complexity is to use a NoC.
Having said this, what do I know? The last time I designed an ASIC was in the early 1980s (no one had heard the term SoC back then). To make sure I wasn’t saying something silly (or, at least, no sillier than usual), I requested a video chat with Michael Frank, who is VP and Chief Architect at Arteris. As part of this chat, I asked Frank: “What are all the reasons SoC designers need to use a NoC?”
It wasn’t long before I was sorry I’d asked, because Michael deluged me with so many thoughts that it left my head spinning like a top. I’m still recovering from the experience but—happily—I have just enough strength left to summarize Michael’s stream-of-consciousness responses as follows:
- The complexity of current SoCs
- Today’s SoCs consist of a large number of purchased and internally developed IP blocks.
- Having many agents communicating with memory and each other using a standard wiring (crossbar) topology is area consuming.
- IP blocks from different vendors and/or carried forward from previous designs may use different interface standards (ACE, AXI, AHB, APB, CHI, OCP, etc.). An NoC usually uses an internal protocol for communication to “wrap” individual interface standard capabilities and hide these in favor of standardized “processing.”
- Silicon technology continues to follow Moore’s Law
- The number of possible components on a chip is increased, which allows more complex systems to be built consisting of more processors and accelerators. More concurrency in computation leads to increased traffic and more concurrent transactions to memory.
- Clock speeds are increased, which means more data processed per unit of time. Faster memory standards (DDR … DDR5) means the overall memory bandwidth increases. Memory latency does not scale (memory wall), so, in order to overcome latency, the system needs to have more memory transactions in flight.
- Traffic aggregation/distribution from many sources (initiators) to many sinks (targets) is a problem that has been solved in other networks, first in telecommunications, then in computer networks, by using a packetized protocol. The same solutions apply to NoCs.
- Managing concurrency in a non-NoC implementation is overly complex and hard to verify and prove correct. NoC protocols allow the decoupling of requests, memory accesses, and returning data.
- Quality of Service (QoS)
- As per point (2.2), multiple concurrent agents have different bandwidth requirements and different latency tolerances.
- Implementing QoS for “flows” in packetized networks is known in the art (even though it often still is an art) from computer and telecom networks, thereby allowing service guarantees to be provided, which is (almost) impossible on switched connections.
- The Introduction of caches
- Shared memory resources require local storage on die (bandwidth multiplication, latency reduction) to decouple external memory (e.g., DRAM) and internal processors/accelerators.
- Introducing caches raised the problem of coherency, which is a contract to guarantee that all sharers of data always have access to the most recent version, and memory consistency, all of which requires rules about the ordering and visibility of modified memory locations.
- Implementing message-based cache protocols with multiple participants is straightforward on a NoC (kind of), but very complex and low performance using conventional (legacy) interconnect strategies.
- System deadlock avoidance
- Coherency processing for shared caches results in a variable number of messages (e.g., snoops, data interventions) spawned off a single transaction request. Tracking and managing the flow of these activities without deadlocks is simpler for NoC (this can be formally verified).
- Resource management (buffers, etc.) is simplified by using retries or credit-based systems, for example.
- Cost of wires
- Process scaling has clearly favored transistors/gates over wires. As a result, the relative density of gates vs. interconnect has become out of balance, leading to significant increase in the number of metal layers (cost). Wires are more expensive and limited in the choices of topology.
- A NoC shares wires between (virtual) connections, thereby increasing wire utilization (return on the cost of wires).
- Noc packetization is flexible. The wire count for less congested routes can be optimized based on expected traffic communication patterns.
- Design simplification and debuggability
- A single, shared protocol stack reduces verification effort and supports inspection by telemetry (performance counters) and live debugging (traffic trace capture).
- Using a NoC decouples the design of local transport/traffic management from global transport.
- Hierarchy support
- Rather than building a complex design in one piece, dividing the design into self-contained, hierarchical blocks is simplified.
- Each block may have independent clock and power control with checks only on the boundaries. This results in more/better power management capabilities.
- Error handling
- A NoC supports the implementation of error detection and recovery/resilience by providing alternate/redundant routes that may be used.
- Timing closure and topology creation
- Individual paths in the network can pass through different clock domains, potentially operating at different frequencies.
- Retiming individual segments by pipelining is straightforward.
Good Golly Miss Molly! As you can imagine, the above list reflects a long conversation. I wish you could have heard it, not least that I wouldn’t have needed to write all this down. Suffice it to say that I for one am convinced that the answer to the question “Who needs a NoC” is a resounding “Everyone!” (This assumes we are talking about folks who are developing SoCs, of course—people pursuing a profession in the ancient art of origami, for example, can almost certainly continue to do so in a NoC-free environment.) What say you? Do you have any thoughts you’d care to share on any of this?



