


It seems that almost every day I hear about some cool and exciting techno-wonder originating with those clever guys and gals in Israel. For example, I currently have a WifiWall Traveler sitting in my shirt pocket. This little beauty, which came from the folks at WifiWall.com, is small enough to fit in the palm of my hand (2.5″ x 1.75″ x 0.75″), yet it’s awesome in its power.
Until recently, I had been happily floating through life in the misguided belief that, so long as I was using a virtual private network (VPN), my Wi-Fi communications were secure. Sad to relate, I now know that VPN works its magic only on layer 4 and higher (of the OSI model) — after TCP/IP has already been established — but layers 2 and 3 aren’t covered at all when you’re utilizing Wi-Fi (sad face).
But turn that frown upside down into a smile, because my WifiWall Traveler knows the MAC addresses of my iPhone, iPad Pro, and laptop computer. What it does is to constantly monitor any Wi-Fi access points in the area and to “sniff” every packet that zips by through the ether. What it’s doing is looking for cyberattacks in the form of rogue access points, evil twin access points, connection hijacks, man-in-the-middle attacks, and so forth.

My WifiWall Traveler makes me happy (Image source: Max Maxfield)
Most of the time, my WifiWall Traveler just buzzes and displays alerts if it detects anything that looks suspicious (as you can see from the photo I just took, it’s spotted 302 dubious players since I left home this morning.) But if it detects an attack on one of my systems — like my iPhone, for example — it will immediately leap into action, sending a Channel Switch 802.11 command instructing the iPhone to kill its Wi-Fi connection, thereby blocking the attack and preserving the integrity of my data and my system.
How can you get one of these bodacious beauties? I’m sad to say that these aren’t available as standalone units at the moment, but only as part of a WiFi Dome installation, which covers an entire facility such as an office block, factory, or airport. The WiFi Traveler allows people to leave the dome while maintaining a bubble of protection around them.
Another example of Israeli ingenuity is the current Makeway Kickstarter, which allows you to create magnificent mesmerizing kinetic art in the form of magnetic modular marble madness (phew). They offer all sorts of kits, from the Basic and Starter packs, to the Standard, Full, and Pro packs, to the Obsession and Even More Obsessed packs. Following the posting of my Magnificent Mesmerizing Magnetic Modular Marble Madness column, one of my chums sent me a message on LinkedIn saying, “I’ve always loved these kinetic sculptures, but they don’t have a ‘Completely Over The Top Bonkers Obsessed’ level.” Happily, there’s no need to worry, because I’m assured that you can take three “Even More Obsessed” kits and use them to form your own “Completely Over The Top Bonkers Obsessed” kit. (I’m a problem solver at heart.)
But none of this is what I wanted to talk about. What I really wanted to discuss was the recent announcement from CEVA — the folks who create the IP used in SoCs to bring us signal processing, sensor fusion, artificial intelligence (AI) processors, and 5G communications for a smarter, connected world.
Introducing the CEVA-XC16
Actually, the guys and gals at CEVA have announced two things. The first is their new Gen4 CEVA-XC architecture, which offers eye-watering performance of 1,600 GOPS, innovative dynamic multithreading, and an advanced pipeline that allows it to attain operating speeds of 1.8 GHz at 7 nm. The second is the first processor to be built on this architecture, the CEVA-XC16, which targets 5G Intelligent Radio Access Networks (RAN) and enterprise access points, providing a 2.5X improvement in peak performance over the previous “latest-and-greatest” CEVA offering.
When chatting with them on the phone, the folks at CEVA told me that the Gen4 CEVA-XC architecture delivers unmatched performance for the most complex parallel processing workloads required for 5G endpoints and Radio Access Networks (RAN), enterprise access points, high-end Wi-Fi access points, massive AI, radar and lidar, and a wide variety of other multigigabit low-latency applications. They also say that the CEVA-XC16 is much more than a DSP core — it’s a complete computing platform. More specifically, they say:
The Gen4 CEVA-XC unifies the principles of scalar and vector processing in a powerful architecture, enabling two-times 8-way VLIW and up to an unprecedented 14,000 bits of data level parallelism. It incorporates an advanced, deep pipeline architecture enabling operating speeds of 1.8 GHz at a 7 nm process node using a unique physical design architecture for a fully synthesizable design flow, and an innovative multithreading design. This allows the processors to be dynamically reconfigured as either a wide SIMD machine or divided into smaller simultaneous SIMD threads. The Gen4 CEVA-XC architecture also features a novel memory subsystem, using 2048-bit memory bandwidth, with coherent, tightly-coupled memory to support efficient simultaneous multithreading and memory access.
Well, it’s hard to argue with logic like that. The quad vector processing units support up to 256 MACs per cycle while the dual scalar processors provide true multithreading. There’s also a new optimized instruction set architecture (ISA) for accelerating key functions, such as dedicated FFT and symmetric FIR, which offers a 2X performance improvement in complex FIR and matrix multiplication as compared to previous generation processors.
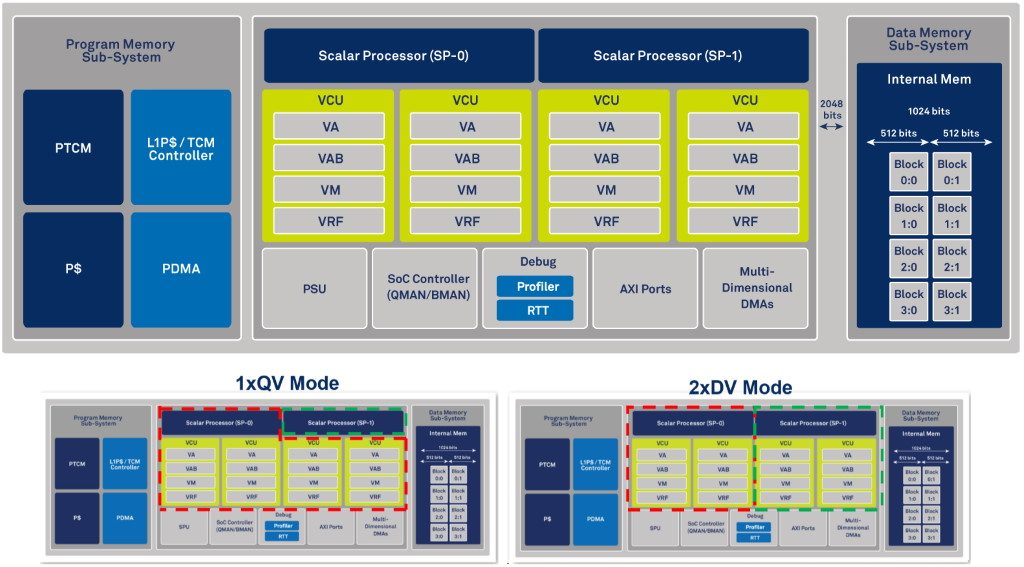
CEVA-XC16 architecture diagram illustrating dynamic multicore modes (Image source: CEVA)
Of particular interest is the ability to dynamically allocate the vector units to the scalar processors. In QV mode, all four vector units are assigned to scalar processor SP-0. By comparison, in DV mode, two vector units are assigned to each of the scalar processors SP-0 and SP-1.
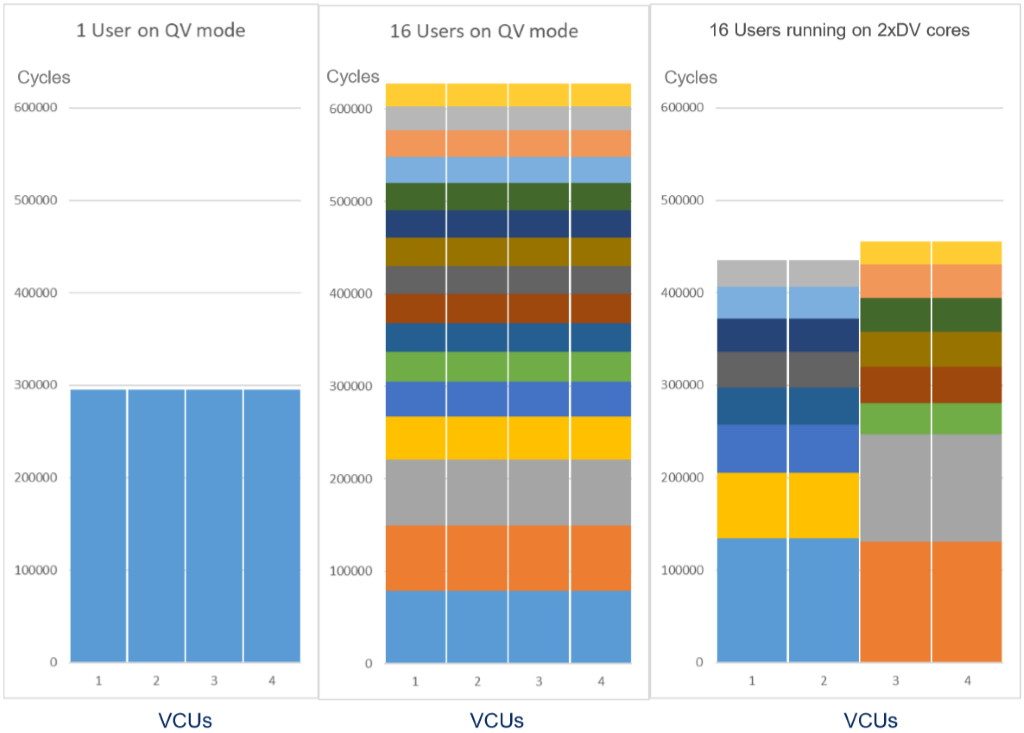
Dynamic multithread example: QV 🡨🡪 (DV x 2) (Image source: CEVA)
The example above shows the case of a 5G NR 4×4 channel estimation task. We start with a single user running in QV mode (left). With 16 users running in QV mode (center), control overhead doubles the overall cycle load relative to single user allocation (in single thread mode). By comparison, significant improvement is seen for the multi-user case when the CEVA-XC16 switches to a dual-thread mode running on 2xDV cores.
A single CEVA-XC16 core is impressive in its own right, and many users may require only one such core as part of their SoC. In reality, however, many designers will employ multiple cores in sophisticated topologies, such as the 5G NR gNB macro base cluster architecture illustrated below.
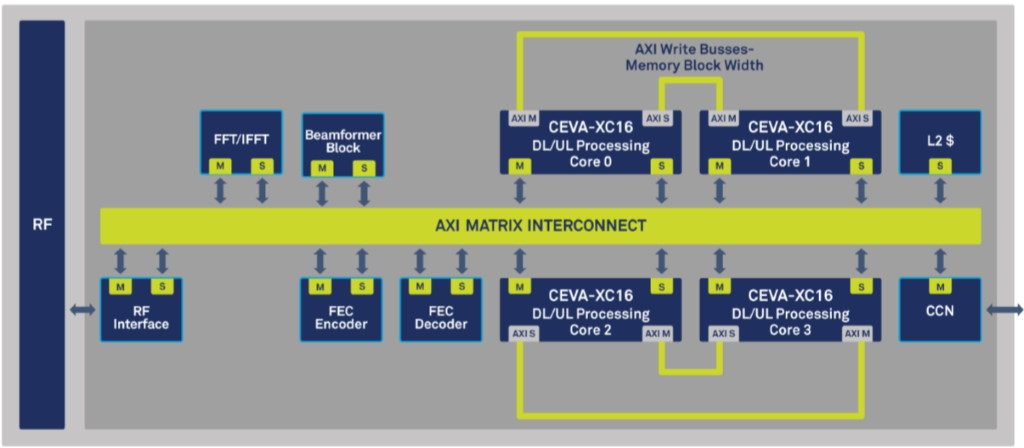
5G NR gNB macro base cluster architecture (Image source: CEVA)
Observe that, in addition to the four CEVA-XC16 cores having access to the main AXI matrix interconnect, they also have their own AXI master/slave back-channels for inter-core communication. The result is that just one such cluster can process 4 x 100 MHz TDD carriers, 128 x 8 MIMO, and 256 QAM with a 125 us subframe, and all with a 35% reduction in silicon footprint as compared to equivalent previous CEVA-XC-based clusters.
Generally speaking, I’m a “glass half full” type of guy. However, I must admit that, every now and again, I’ve had my doubts as to whether the promised 5G rollout is going to take place in the timeframe we’ve been promised. And then something like the CEVA-CX16 comes along to bring a twinkle to my eye and plaster a cheesy smile back on my face. I have to say that I, for one, cannot wait to see the day when 5G and augmented reality meet Super Bowl 2025, for example. How about you? What are your thoughts on all this?



