


I sometimes feel like I’m listening to a broken record when a company calls to tell me about the wonders of their new artificial intelligence (AI) processor. I try to say “Ooh” and “Aah” in all the right places, but oftentimes my heart isn’t really in it. Every now and then, however, I do get to hear something that makes me sit up in my seat and exclaim, “WHAT? O-M-G!”
I honestly believe that “WHAT? O-M-G!” is what you are going to say upon reading this column, but before we plunge into the fray with gusto and abandon…
Rarely does a day go by that I’m not exposed to some hot-off-the-press AI-related topic. For example, my chum Joe Farr just emailed me to say that he asked the ChatGPT chatbot, “Could you write a program in C# that acts as a BASIC interpreter?” As Joe informed me, he was surprised by the response, which I’ve summarized as follows:
It proceeded to give me a complete C# program listing. Not a fragment or snippet, but a complete bloody program listing along with an example of it working. You can see the darn thing typing out the code in front of your eyes… in real-time. It’s really frightening to watch.
I’ve documented Joe’s experiments in more detail in a Cool Beans Blog: Using ChatGPT to Write a BASIC Interpreter. As part of that blog, I also made mention of the new American science fiction horror film M3GAN (pronounced “Megan”), the watching of which will also have you sitting up in your seat exclaiming “WHAT? O-M-G!” (I speak from experience).
Returning to the topic in hand, I was just chatting with the cofounders of a company that has only recently emerged from stealth mode. Winston Lee (CEO) and Shashi Chilappagari (CTO) founded DeGirum.ai in 2017, and the company is already offering sample modules featuring their ORCA-NNX (Neural Network Express) device.
“Good Grief, not another AI accelerator,” I hear you muttering under your breath. Trust me, what I’m about to tell you will dispel your cynical attitude and leave you clamoring for more, in which case, you’re welcome. Of course, if you build your own AI accelerators, you may be less enthused by the news I am about to impart, in which case, I’m sorry.
As Winnie-the-Pooh famously said, “For I am a bear of very little brain, and long words bother me.” I also am a bear of little brain, and I feel the same way about long presentations. I like a simple story that I can wrap my brain around, so it can be disconcerting when a company assaults me with a presentation featuring so many slides that I start to fear it will never end. Thus, you can only imagine my surprise and delight when I was presented with DeGirum’s 4-slide offering.
We commenced with Slide #1 as shown below. Shashi made mention of the fact that trying to work out whose AI accelerator was the best is a non-trivial task, not the least that the concept of “best” may vary from model-to-model and application-to-application.

Evaluating AI hardware is hard (Source: DeGirum.ai)
It doesn’t help when some people talk in terms of tera operations per second (TOPS) while others make their claims based on frames per second (FPS). And then there are those who boast of their offering with tall tales of TOPS/Watt, TOPS/$, FPS/Watt, and FPS/Dollar. Just to add to the fun and frivolity, we may not end up talking in terms of real units because cunning marketeers are not averse to “normalizing” (some may say “obfuscating”) their metrics in terms of price, power, or performance.
As Pontius Pilate said (well, warbled) in Jesus Christ Superstar: “And what is ‘truth’? Is truth unchanging law? We both have truths. Are mine the same as yours?” If I didn’t know better, I’d say Pontius had spent too much time perusing data sheets from different AI accelerator vendors.
Even the simplest things can be hard to measure, and the aforementioned terms don’t mean the same for everyone. One AI accelerator’s data sheet may quote twice the TOPS of someone else’s offering, but that doesn’t mean the end application will run twice as fast.
Take TOPS/Watt, for example. Are we just talking about the matrix multiplication unit, or the whole system-on-chip (SoC) power, and are we also taking any DDR memory, PCIe, and other peripherals into account? These nitty-gritty details are rarely made clear in a product sheet.
If we are looking at statistics associated with an accelerator, we may not obtain the same results with different host processors. Even values associated with the accelerator itself can vary from model to model. And, perhaps most importantly, the real application is never running only the AI model. In the case of a visual processing task, for example, the application will also be doing things like decoding, resizing, and otherwise processing a video feed and making decisions and performing actions based on what the model detects.
ResNet-50 is a 50-layer convolutional neural network (48 convolutional layers, one MaxPool layer, and one average pool layer). If someone says “We can run XXX frames per second of a ResNet-50 model” in their AI accelerator datasheet, this doesn’t actually mean much of anything to an end application developer.
And, if you are architecting a new system, there are a bunch of potential hardware restrictions that have to be taken into account. What types and sizes of model can the AI accelerator accommodate? How about input size, precision, and the number of models that can be running at the same time?
As a parting thought before we move on, how would one set about comparing an AI accelerator that is very efficient but limited in what it can run to an accelerator that can run almost anything but is not as efficient. Which is best? How long is a piece of string?
Well, we all know how difficult this stuff can be, but it’s refreshing to hear a vendor saying it out loud. By this time, I was nodding my head and agreeing with everything Shashi and Winston said, at which point they whipped out Slide 2 showing their ORCA-NNX chips on two M.2 modules (one with external DDR and one without).
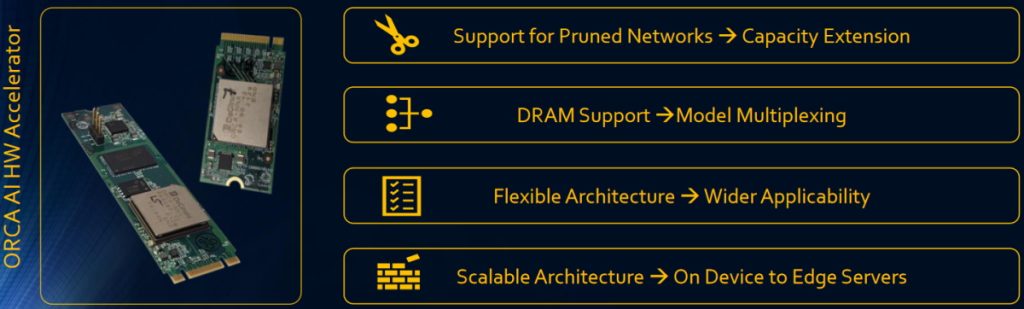
ORCA-NNX chips presented on M.2 modules with and without DRAM
(Source: DeGirum.ai)
This is when they started to batter me with information pertaining to the ORCA-NNX, which—I now know—supports vision models and speech models (and other models), large models and small models, pruned models and dense models, floating-point models (Float32) and quantized models (Int8), and that’s just the beginning. In addition to DRAM support, along with PCIe and USB interfaces, ORCA-NNX also supports efficient model multiplexing, multi-camera real-time performance, and multi-chip scaling, where the latter means you may run one or two (or more) ORCA-NNX accelerators in an edge device, or even more ORCA-NNX accelerators in an edge server, all without changing the software.
And, speaking of software, we are talking about a fully pipelined AI server stack, simple and convenient Python and C++ SDKs, intuitive APIs for rapid application development, model pipelining and parallelization, support for a wide variety of input data types including (but not limited to) images, camera feeds, audio and video streams, and video files, all coupled with automatic and efficient scaling for multiple devices.
“Hmmm, this all sounds mighty impressive,” I thought, “but what does the ORCA-NNX architecture look like and how does this compare to the competition?” I think Shashi was reading my mind, because this is where we transitioned to Slide #3 as shown below. Well, not exactly as shown below, because I’ve blurred out the company and product names associated with any competitors. The folks at DeGirum say: “When we publish numbers officially, it is our duty to report the conditions in which we measured them or if we have obtained them from other sources,” and they prefer to keep some information on the down-low for the moment. They did reveal that the vertical axis is in terms of FPS, if that helps.
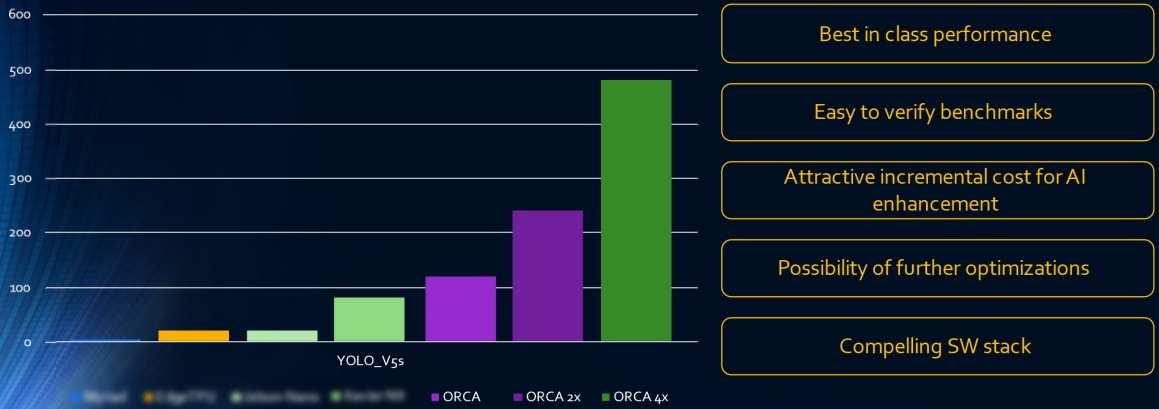
Application performance (Source: DeGirum.ai)
From PyTorch we are informed that, “YOLOv5 is a family of compound-scaled object detection models trained on the COCO dataset and including simple functionality for Test Time Augmentation (TTA), model ensembling, hyperparameter evolution, and export to ONNX, CoreML, and TFLite.”
The results from YOLOv5s using single, dual, and quad ORCA-NNX implementations are shown in the three columns on the right. As we see, even a single ORCA-NNX outperforms its nearest competitor.
So, where we are in this column at this moment in time is we’ve been told that (a) it’s very hard to compare different AI accelerators, (b) everyone quotes different numbers, (c) DeGirum’s ORCA-NNX outperforms the competition, and (d) DeGirum marry their powerful hardware with intuitive and easy-to-use software that helps developers to quickly create powerful edge AI applications.
“But these are the same claims everyone makes,” I thought to myself, with a sad (internal) grimace.
“But these are the same claims everyone makes,” said Shashi, with a wry smile.
Not surprisingly, this is a problem the guys and gals at DeGirum encountered very early on. They would meet and greet a new potential customer, explain that they had the best hardware and even better software, and the customer would immediately respond that everyone else was saying exactly the same thing.
This is when Shashi introduced Slide #4 (he did this with something of a flourish and with a silent “Tra-la,” if the truth be told). In order to silence the skeptics, the chaps and chapesses at DeGirum have introduced something they call the DeLight Cloud Platform as shown below:
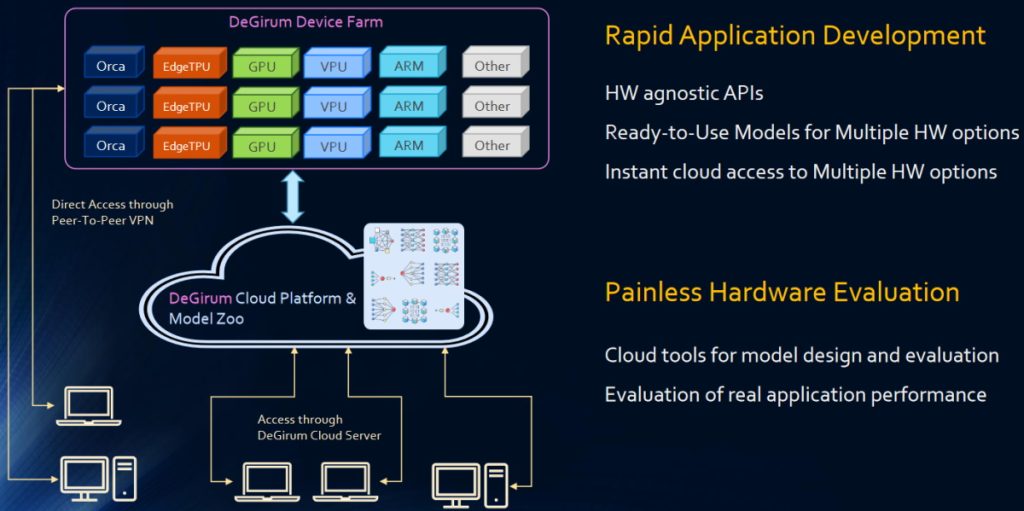
DeLight Cloud Platform (Source: DeGirum.ai)
And what a delight it is (I’m sorry, I couldn’t help myself). The idea behind the DeLight Cloud Platform is that, rather than simply say “we are the best,” the folks at DeGirum decided to let users prove this for themselves.
As Shashi told me, people want to be able to compare and contrast AI accelerator application performance, but doing this in a rigorous manner means purchasing a bunch of platforms, creating software, porting it to all the platforms, checking that everything is working as planned, and performing an analysis in terms of power, price, and performance to see which one comes out on top. Not surprisingly, however, obtaining the hardware, loading the necessary drivers, installing the full software tool chain, and developing even a simple test application can consume a substantial amount of time and resources.
All of this is addressed by the DeLight Cloud Platform. First, we have the DeGirum Device Farm which includes ORCA-NNX platforms from DeGirum, Edge TPUs from Google, and GPU lines from Nvidia, along with VPUs (a general term for accelerators coming out from Intel), ARM-based SoCs, and others that will be added as their hardware and software becomes more widely available.
Next, we have the DeGirum Model Zoo, which boasts a collection of ready-to-use models. Users can employ DeGirum’s hardware-agnostic APIs to start developing applications on their client-side Windows, Unix/Linux, and Mac hosts. In the not-so-distant future, the folks at DeGirum plan to add a BYOM (“bring your own model”) capability.
All this means users can load a model and instantly start developing a test application. Once they have their application working, they can use the DeLight Cloud Platform to evaluate all of the hardware options.
One of the major pain points in today’s model design, training, and porting processes is that, by the time you try to make your model work on your selected hardware, it may be too late to discover that the model is not, in fact, well suited to that hardware. The folks at DeGirum say they’ve flipped the process around so you can start with the hardware first.
The primary difference between a trained and untrained model are its weights, which means you can evaluate an untrained model’s compatibility, speed, and portability on day one without having to train the little rascal. Once you know your model will work on the selected hardware, you can train it, prune it, quantize it, etc. And, once you’ve developed your real-world application on the DeLight Cloud Platform, you can use the same software to deploy this application onto your edge devices.
The applications for edge AI are essentially limitless, including surveillance, smart homes, smart buildings, smart cities, robotics, industry, medical, manufacturing, agriculture (e.g., AI-equipped drones detecting weeds or fungal outbreaks and applying pesticides and insecticides in small, focused doses—see Are Agricultural Drones Poised to be the Next Big Thing?).
Creating state-of-the-art edge AI accelerators provides tremendous opportunities for small, innovative companies like DeGirum, but only if they can convince users that their technology is worth investigating. As far as I’m concerned, offering the DeLight Cloud Platform is a masterstroke (I’m reminded of the Brilliant! Guinness adverts because I want to exclaim “Brilliant!”). What say you?



