


Hey there! Well it looks like you’ve just launched a full-chip analysis of your project, so… well, you’re gonna have some time on your hands. While you’re awaiting results, let’s talk about some ways that we might reduce that spare time (assuming that you’re not counting on that spare time for getting other things done – or just relaxing).
EDA has always struggled with run times. And that’s because EDA tools have a huge job, taking big designs (some might not seem big today, but in their day, they were) and identifying problems or optimizing or whatever in a timeframe that seems long when it comes to sitting around waiting for results, but is still far faster – and more accurate – than a human (or a bunch of humans) could do.
Each time run times have felt out of control, the big EDA folks have come out with new, improved, accelerated versions of their programs. And, in some cases, this involved parallel computation of the solutions. The parallelism invariably would come in one of two flavors – and occasionally both: multiple core support within a single box or multiple box support.
But not all algorithms are well suited to parallel computation. Or maybe the dimensions along which partitioning might work might not be obvious. So some tools have had more success than others in keeping the data moving. Much effort has been placed on so-called “in-design” approaches, where live engines can process small, local versions of parasitic extraction or timing analysis or whatever while the main program is underway, helping designs to converge with fewer repeat cycles.
As far as I can tell, all of these efforts have been done individually by each company for each tool and algorithm. There has been not much of a general solution or fundamental change of approach. But Ansys’s recent announcement suggests something new, thanks to a largely unrelated area of technology.
Big Data’s your Daddy (in this case, not your Big Brother)
Off in the world of “scoop up all publicly available internet data and slice it a million ways so we know everything about everyone,” technologists have had to learn how to manage huge volumes of unstructured data in a way that scales and can stay ahead of the rate of data generation. This is lovingly referred to as Big Data.
There are numerous aspects to the Big Data discussion. Some of it relates to tools and techniques that are fast evolving to move the technology forward. Others voice a (all too often ignored) concern about the impact of possible loss of privacy as we rush to meet the insatiable demand (by marketers, not by consumers) for more targeted advertising.
But away from all that buzz of activity, others are taking a look at the fundamental Big Data approaches and are realizing that they might be useful elsewhere (and without the social questions). Ansys’s SeaScape platform is based on Big Data techniques.
For any of you not immersed in the world of Big Data, there are some concepts to review here as to how queries and analytics work. In principle, you take a big chunk of work and split it into smaller chunks, each of which gets calculated, and then the partial results get brought together into a final result.
The partitioning portion involves splitting the data into so-called “shards.” (This is reminiscent of shards of glass, presumably, although Wikipedia points to some other possible sources of the word. This has had the unfortunate development of conversion into a verb, so now you hear about a tool “sharding” the data.)
This probably sounds like old-fashioned parallel partitioning, but there are some differences. When splitting up a database, for instance, large tables may be partitioned by row, while small tables may be replicated with each shard. It’s that last bit, along with the ability to partition multiple instances, that separates sharding from “horizontal partitioning.” The key is that every shard is self-sufficient – there is no data shared between shards.
So that’s the “split up the data” portion. The “bring the partial results back together” portion is generally referred to as “MapReduce,” based on a first mapping step that organizes what data gets processed on which processor and a subsequent reconciliation step.
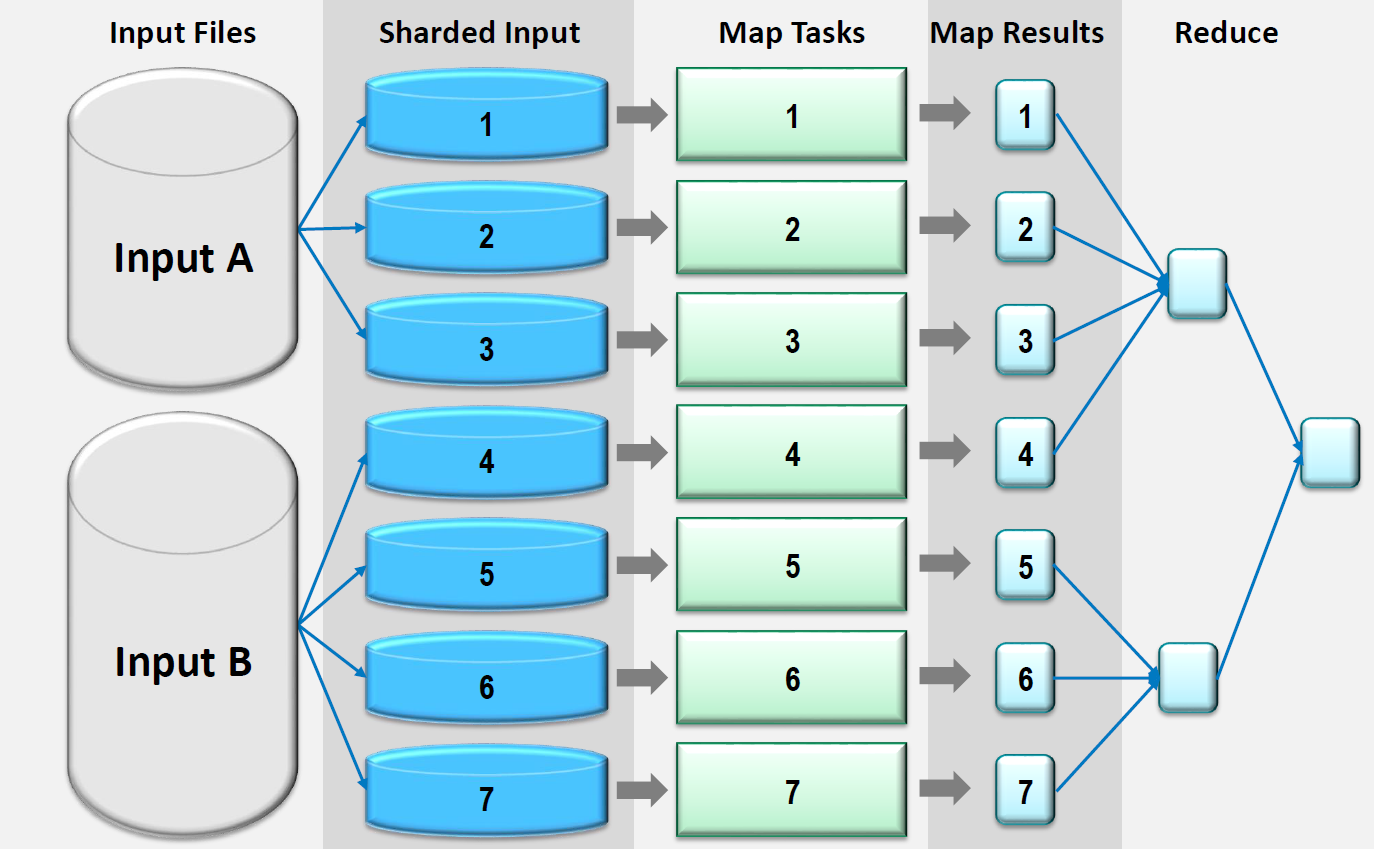
(Image courtesy Ansys)
I tried playing around with some trivial examples to get a sense of how this works. Let’s play with simple averages. Let’s say we want to calculate an overall average of a number of data points. We first need to split up the data, and let’s say that, for regional reasons, we end up with four unequal shards:
– [3,5,7]
– [1,2,3,4,5]
– [29,52,16,22]
– [15,9,87,16,55]
We can reduce this by calculating the average on each row and then calculating an overall result from the partial averages. The trick here is that, because of the unequal sets, you need to return not just the partial averages, but also the number of data points that created the average. So you might end up with the following set of partial results: [(5,3),(3,5),(29.75,4),(36.4,5)]. To get the final reduction, you multiply each average by the number of points in the data set (giving a weighted average for each set), add that result all together, and then divide by the total number of data points. Boom: 19.5.
If this were a matrix where blank cells are zero, then it gets easier, since each set now has the same number of cells. You no longer need to return the number of data elements with the partial result. For the above, the matrix would be
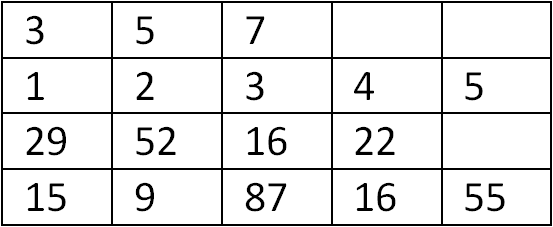
The average from this will be slightly different, since we have some zero cells now. Simply average each row and then average the row averages. Boom: 16.55.
Unfortunately, not all calculations are so straightforward. And, most critically, the real world doesn’t always provide for clean sharding. Tiling up a die, or organizing by nets or by some other parameter, may artificially isolate elements from each other. Take a tile: the transistors at the edges of the tile may be influenced by what’s going on in the adjacent tile, but, once sharded, that adjacent tile doesn’t exist. Each shard presumes itself to be self-contained – a complete universe unto itself – and it’s a simplification, not necessarily reality.
That makes calculations easier, but it ignores the fact that those cross-tile interactions can, in fact, matter. Do they matter a lot? Maybe, maybe not – depends on the specific problem – but if the goal is to achieve accurate, sign-off quality results, you can’t pretend that tiles are independent if they’re not.
So now you get all these results for each tile and start to do the reduction. How do you account for cross-tile effects? There’s no one answer for this; it depends on the interaction being modeled. In general, you need to incorporate some stitching into the reduction algorithm.
I made up a totally arbitrary, stupidly simple example from the matrix above. What if the rows weren’t totally independent? What if, for some reason that’s beyond me (because I’m making this up), you need to augment the average for each row with 10% of the row above and below? (With exceptions for the top and bottom rows, which take 10% only from the row below or above, respectively.) In other words, the numbers you’re averaging aren’t just the numbers x[i,j] summed along row i, but the sum of x[i,j] + 0.1(x[i-1,j] + x[i+1,j]). (This is vaguely reminiscent of evanescent fields in the world of photonics…)
Well, now you get the partial averages, which don’t account for the cross-row impact because they’re calculated with no knowledge of any other row; they’re just the first term in the expression above. Once we get our partial results, instead of averaging them all, we first need to take each partial average and add 10% from the average below and above (with accommodation at the top and bottom). Here we’re stitching together the artificially separated rows to account for their interaction. Slightly more calculation, but not much. Boom: 18.875.
From Trivial to EDA
OK, those examples were ridiculously trivial as compared to anything really being done in EDA. But the concepts hold. This is what Ansys is setting up for their tools with their SeaScape Big Data platform. It’s not a product per se, although they have announced SeaHawk, a new chip/package/board power integrity solution that operates on this platform.
It’s suitable for in-design analysis, although it’s still 2-6% out of correlation with their flagship RedHawk tool – a number that’s improving as they continue to tune things. They say that, at this point, inaccuracies are less about algorithms and more about parallelism simplifications. Meanwhile, RedHawk is being massaged to operate over SeaScape in the future. Specific numbers aside, they claim that, if you use SeaHawk while designing, then it’s extremely likely that the full-chip design will pass muster with RedHawk for sign-off.
And, looking beyond simple silicon design, they also see this as helping with multi-physics design. Right now, that’s handled mostly by independent tools operating in their own silos. Doing multi-physics optimization is simply too complex to be done with a single monolithic program on the complete dataset. But once you’ve sharded the data, it becomes tractable.
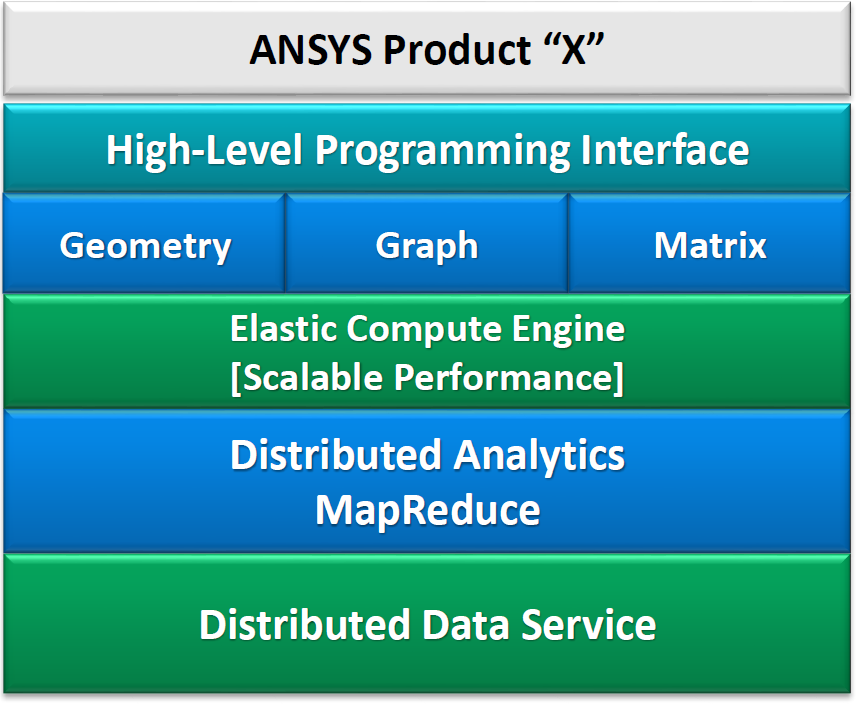
(Image courtesy Ansys)
One of the main benefits of the system is the simpler computing hardware that can be used. According to Ansys, the typical EDA machine needs 256 GB of memory or more, along with expensive filers. It may allow multi-threaded or distributed processing, but scaling is limited.
SeaScape allows processing on a larger farm of typical cloud servers, which have only 16-32 GB of data and cheap local storage. Oh, and there are thousands of them, along with a robust load-sharing facility (LSF) for dispatching the shards.
Of course, this brings us into the realm of cloud computing for EDA – the oft-tried, seldom successful notion of leveraging all these cloud servers to design chips. Problem is, of course, as always, not enough people trust that their crown jewels will remain safely away from prying eyes in the cloud.
While that might seem to put a question mark by Ansys’s efforts, they note that many of their big customers have extensive in-house farms – private clouds. And Ansys has arranged what they refer to as a “virtual private cloud (VPC), which they’d eventually like to transition into a full-on public cloud for all those Internet of Things (IoT) designs they anticipate coming their way.
Underachieving is Good?
Finally, they’re using this to bolster the notion of under-design. Right now, based on the difficulty of doing concurrent multi-physics optimization, designs are optimized along individual axes, resulting in overdesign.
With more capable tools, they’re promoting the idea that you should start with an under-designed chip. You can then do analysis to identify specific parts of the chip that need shoring up. At that point, you can make surgical fixes – a bit of metal here, a bit of space there – to make sure that current and voltage drop and EMI and electromigration and all of the other potential bugaboos are addressed with the minimum of fuss. They anticipate real die size savings out of such an approach.
As a reminder, SeaScape is an underlying bit of infrastructure that can – and, if they have their way, will – be used to host a variety of compute- or data-intensive design tools. I asked whether they might be tempted to license the platform out to others. They said that they’ve been asked, but have no present plans to do so.
More info:



Do you think that Ansys has cracked the code for scaling algorithms with their big-data approach?