


Sometimes I try to capture a column’s intent in a short, snappy title using pithy prose, as it were. I might attempt an aphoristic or epigrammatic turn of phrase while trying not to appear gnomic (which—as we now see—is something I reserve for my opening sentence).
In this case, however, my Speeding AI and HPC Workloads with Composable Memory and Hardware Compression / Decompression Acceleration offering is as short and snappy as I could make it with respect to the topic about which I’m poised to pontificate.
My head is currently spinning like a top, because I was just chatting with Lou Ternullo, who is Senior Director Product Management Silicon IP at Rambus, and Nilesh Shah, who is VP Business Development at ZeroPoint Technologies.
In a crunchy nutshell, the problem we are talking about here is the high cost of memory in the data centers used to perform artificial intelligence (AI) and high-performance computing (HPC). But turn that frown upside down, because the guys and gals at Rambus are collaborating with the chaps and chapesses at ZeroPoint to provide a super-exciting solution (said Max, super-excitedly).
The typical setup—the one that’s still dominant in the market today—is for servers to have their XPU processing units (CPUs, GPUs, NPUs, TPUs, etc.), DDR memory, and SSD memory (in the form of NVMe drives) located within the same physical unit. This is the standard server architecture, especially in traditional data centers, because this setup is well understood, widely supported by operating systems and applications, and offers simplicity in terms of latency, consistency, and management. For example, consider a representative server as shown below:

Example traditional server (Source: Rambus and ZeroPoint)
In this case, there are two CPUs (the big silver chips in the middle), each supported by their own local DDR5 memories, both sharing a bunch of NVMe drives. The problem is that when an AI or HPC workload is assigned to this server, it needs to work with whatever resources are available.
This often results in the over-provisioning of memory to address worst case workloads. As a result, the memory cost can be ~50% of the server cost. (Eeek!)
In the case where an XPU requires more memory than is available to it, it typically has the ability to increase capacity via a non-uniform memory access (NUMA) hop, which means that XPU 0 can access the memory attached to adjacent XPU 1, or vice versa, but that means that one of the XPUs is no longer being used to perform computations—it’s just being used to access additional memory (sad face).
Things get worse. In the real world, most workloads don’t require the full amount of over-provisioned memory. In fact, on average, the typical amount of unused memory, which may be referred to as “stranded memory,” is ~40% of the total memory on the server. Eliminating this stranded memory would save ~20% of the server cost, thereby significantly reducing the total cost of ownership (TCO).
One emerging trend to address this issue is to employ a disaggregated infrastructure, which means that different resources—XPUs, DDRs, SSDs, etc.—are decoupled and made available as “pools” in independent, scalable units. The idea is that each workload can be assigned whatever resources are required. The term “composable” is used to reflect the fact that solutions are composed on the fly from multiple constituent elements. When a workload stops running, those resources are returned to their “pools” to await reassignment to new tasks.
One of the biggest concerns with disaggregation is the added latency in accessing memory when it’s physically distant from the XPUs. To solve this, technologies like CXL (Compute Express Link) are being developed, which aim to provide high-speed, low-latency interconnects between processors and disaggregated memory resources.
This is the point where the guys and gals at Rambus leap onto the center of the stage with a fanfare of sarrusophones (my ears are still ringing). The folks at Rambus have been heavily involved in CXL development, particularly in providing CXL-related intellectual property (IP). Their contributions include technologies that help enable high-performance interconnects between XPUs and memory devices. Rambus offers CXL controller IP, which is critical for implementing the high-speed signaling required by CXL.
CXL allows different types of memory—like DRAM, storage-class memory (SCM), and persistent memory—to be shared between processors and accelerators, improving overall system performance and efficiency in data centers. Rambus’ technology helps deliver the necessary high-speed, low-latency connectivity that is fundamental to this.

Using disaggregated composable memory reduces TCO (Source: Rambus and ZeroPoint)
In the case of the composable memory solution, the diagram above is somewhat simplified because multiple servers can access the same pool of shared memory. The fact that a large pool of memory can be shared by multiple servers/XPUs addresses the over-provisioning problem and dramatically reduces the total amount of memory that is required by the data center.
Is there anything more than can be done? I’m glad you asked, because this is the point when the chaps and chapesses from ZeroPoint join the folks from Rambus at the center of the stage with a blare of bimbonifonos (once heard, never forgotten). The folks at ZeroPoint have developed state-of-the-art compression IP that can offer 2X to 4X compression on the data stored on CXL direct attach memory cards or in CXL shared memory pools.

Adding 2X to 4X compression (Source: Rambus and ZeroPoint)
There are two ways to look at this. If you can compress the data to half its size, you need only half the amount of memory. Alternatively, you can store twice the data in the same amount of memory.
I should point out that the image above can be a little misleading. I initially took this to imply that the ZeroPoint compression and decompression took place on the server side of things. However, it turns out this is not the case. Some companies do perform server-side compression and decompression in software running on the XPU. However, data published by Meta and Google indicate that they spend about 5% of their XPU cycles performing administrative tasks like compression and decompression in software, which equates to losing real money for them because they could be renting those XPU cycles out for revenue.
Furthermore, for a variety of reasons, including not wishing to make any modifications to applications, hyperscalers like Meta and Google have written a spec for composable memory with CXL, and they put in this spec that they want the compression and decompression to be performed on the memory side specifically for CXL.
As an example of the Rambus+ZeroPoint collaboration, see the turnkey FPGA CXL expander card shown below. The Rambus CXL IP and the ZeroPoint DenseMem compression and decompression IP are all running on an Altera (Intel, as was) FPGA, providing access to an additional 128GB of DDR4 memory.
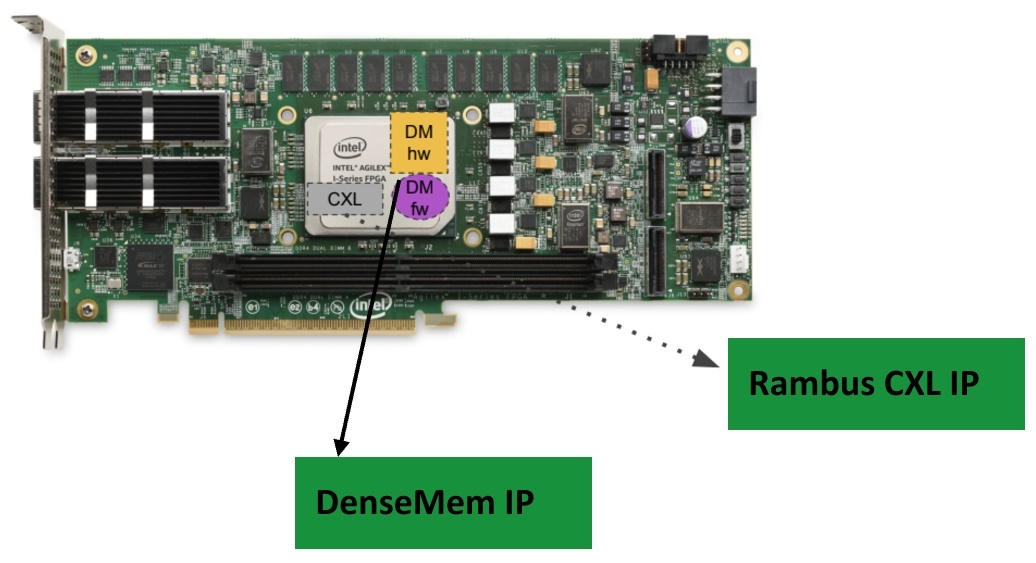
Example turnkey CXL expander card (Source: Rambus and ZeroPoint)
Since compression and decompression are performed in hardware, their effect on latency is almost imperceivable. This end-to-end solution is compatible with things like TPP (transparent page placement), host kernel software, telemetry, and… the list goes on.
Well, I, for one, am very impressed, which is perhaps not surprising since I really don’t understand any of this. I’m most happy when working with a bare-metal application running on an 8-bit microcontroller. I have no idea how people wrap their brains around things like today’s data centers running AI and HPC applications, so I’m delighted to discover that the folks at Rambus and ZeroPoint are there to oil the metaphorical wheels and to keep things rolling quickly and efficiently for the rest of us.
What say you? Do you have any thoughts you’d care to share on any of this? As always, I welcome your insightful comments, thought-provoking questions, and sagacious suggestions.



Localised compression/decompression can/could increase memory access speed too. … Now wondering if cache memory can store eg ranges where the contents are similar, eg 000200..+1ff, all storing c001??
Split the range with a value, and it changes to two ranges and a value, or some other compression method. It only needs to be a fairly simple/fast compression method, to show fairly good results. Most of the stuff zipping between the SoC and RAM will be fairly compressible stuff; there’s just a lot of it.
Hi there — thanks for your comment — I’ll ask the folks at Rambus and ZeroPoint to respond — Max
Great observation, compression/ decompression can certainly reduce overall latency and memory access times by increasing hit rates in the cache! Could you expand on your other question about similar content?