


Funny how, right after I put out my previous audio story, I suddenly started receiving more audio news than ever. So I’ve collected a few of the announcements to breeze through today. Each was selected for some interesting piece of what was going on.
Knowles Does Amazon
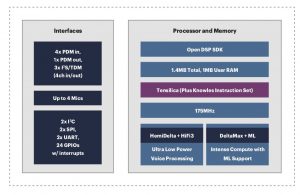
Knowles announced their latest AISonic device, the IA8201. This device reflects the focus that the industry has on improving solutions for smart speakers. It’s a dual-core four-mic device that complements the quad-core eight-mic device they already have out.
The two cores aren’t the same. The smaller Tensilica HiFi3 one is for lower-power wake-word detection. Yeah, a familiar topic. The larger DMX core is intended for much more intensive computing on a live audio stream. It’s also based on a Tensilica core, but it has a proprietary custom instruction set. It handles the harder tasks, like barge-in and multi-mic beamforming. Interestingly, both cores have deep neural-network capability (as well as FFT and “peak-finding” skills).
Part of what’s been challenging for them about this is the fact that the overall packaged solution now contains a MEMS mic, an analog ASIC, and a digital processing chip (which has the two cores). Packaging has historically been a pain in the… ear for the MEMS microphone industry. Having more chips in the package doesn’t help, as it complicates the acoustics – a challenge that Knowles had to work through.
The DSP is open in that third-party algorithms can be used in addition to or instead of the Knowles proprietary algorithms.
(Image courtesy Knowles)
They also announced a reference design for headphones, headsets, and earbuds intended for Alexa use. These devices experience background noise that’s not typical for an in-home Alexa speaker. It connects to Amazon directly through their Bluetooth-connected phone app. This provides hands-free control both of the sound in the headphones but also for any standard Alexa command.

(Image courtesy Knowles)
Maxim Goes Louder, Lower
Maxim announced a few new capabilities, a couple of which we’ll look at here. First, they revealed a new amp that they say provides both 2.5 times more loudness and lower bass. It’s intended for better sound in small-form-factor speakers. They call it DSM, or Dynamic Speaker Management, and the intent is to allow harder driving up to the thermal limits of the system. It’s a 10-V volt solution instead of a 5-V one, and they use combined current-voltage sensing to protect against overdrive and thermal overrun.

(Click to enlarge; images courtesy Maxim)
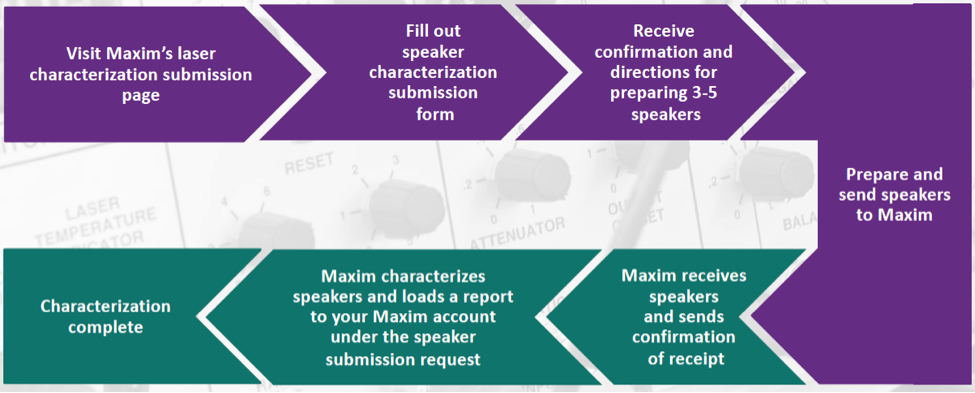
They also addressed another real-world challenge when creating speakers: speaker characterization. In order to create the best sound, the processing must account for the acoustics of the physical speaker. That means characterizing the speaker first, and that can be a chore. So Maxim is offering to do that characterization for you if you send the speakers in to them.
(Click to enlarge; image courtesy Maxim)
Vesper with More Piezo
Vesper had a couple of announcements for two different microphones, leveraging their piezoelectric MEMS microphone for various applications. The first is their VM2020, which won’t break no matter how loud you shout at it. OK, perhaps that’s slightly overstated, but this mic can handle sound above 150 dB (the level where your eardrums can burst) with 1% distortion. They say they’ve taken it as far as 170 dB.
They intend this for use both in high-end speaker systems or soundbars and for industrial applications where the speaker will be near loud machinery. One of the applications can be for monitoring equipment vibrational noise so that changes can be detected and a replacement made before something breaks catastrophically. Example installations might be on server fans or wind turbines.
They’ve also used it as a woofer feedback mic, since they say that too much bass can screw up the sound at a voice mic. Directly measuring the bass helps to correct this – assuming the woofer and voice mic are in the same box (like a smart speaker). They can also use it to improve the sound of a subwoofer by correcting some of the non-linearities.

(Image courtesy Vesper)
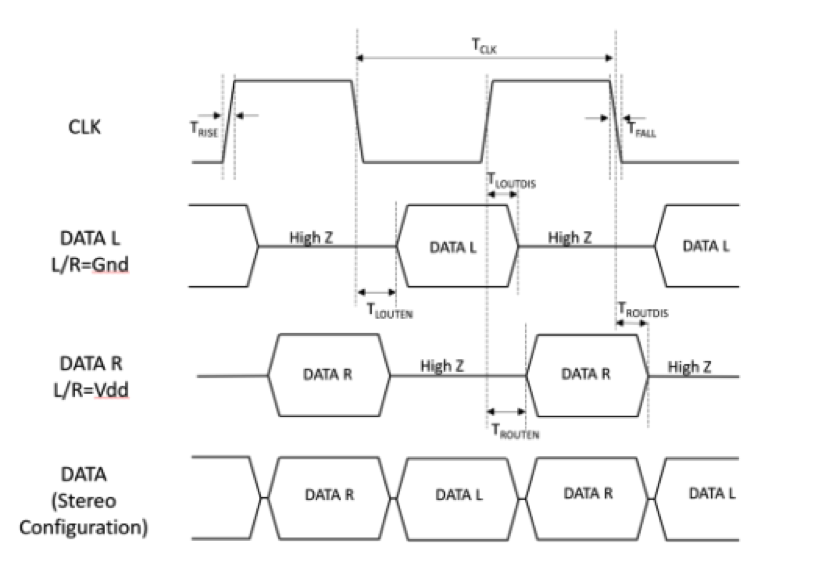
Then they’ve announced the VM3000, which is intended for more pedestrian use without distortion in noisy environments (although not necessarily super-loud noise). The interesting thing I noticed here is that it provides a pulse-density modulation (PDM) output that can be multiplexed with the signal from another mic.
PDM represents sound digitally by the number of pulses in a given timeframe. If that’s the case, it’s hard to picture how you might multiplex two signals, since it would seem that the signal from one would mess up the signal from another. It’s not like there’s a quiet region that could be used for something else.
Or is there? I asked about this, and it turns out that it’s a DDR-like thing. The mic has a signal that sets whether the output is driven by the rising or falling edge of the clock. To multiplex stereo sound onto a single data line, you set one side to output on the rising edge and the other to output on the falling edge. As long as you can demux this, you’re good.
Of course, this multiplexing scheme doesn’t extend beyond 2…
(Image courtesy Vesper)
New Basic Speaker Construction
For the last bit, we move away from the micro-scale on which we’ve been focused. Really, much of what’s new and different in the audio world emanates from the desire to miniaturize everything. After all, standard old speakers are so, well, old, right?
Yes, standard old cone speakers are old. But it turns out that there’s something new in the way of macro-sized speakers. And it has to do with how they’re built. And I’ll ask your indulgence as we look at something that, on its own, isn’t strictly electronic.
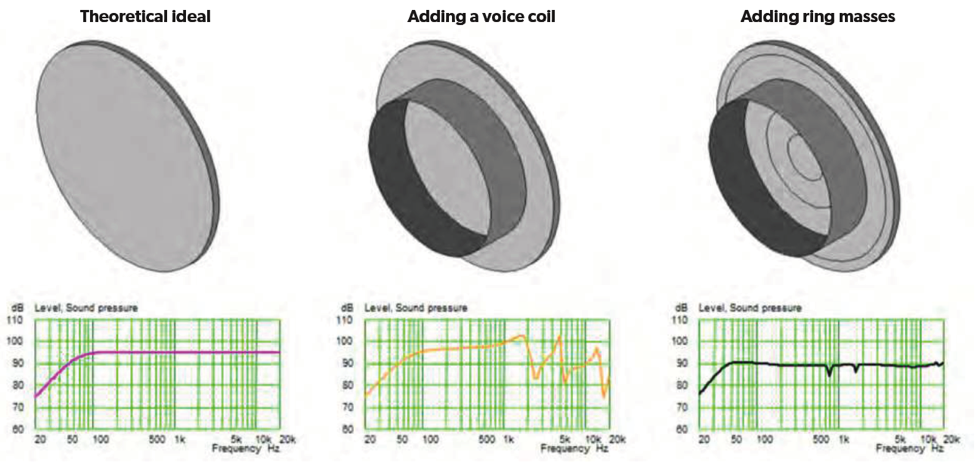
For a standard speaker, we’ve wanted something to move the air in all directions with good sound quality anywhere within the listening area. The ideal way to do this is with a “piston” that moves the air to create the sound. By piston, we mean something that moves as a unit, without all the fiddly vibration modes that materials entertain when producing sound.
That piston has historically been made of a cone of paper. The cone shape keeps it rigid; if it were just a flat sheet, then, well you’d get all of those pesky modes. But, as it turns out, you can still get modes. When the “bending” wavelength in the cone starts to approximate the size of the cone or smaller, then you get modes. This is called breakup. And when the wavelength in air starts to approximate the size of the piston, what was sound with no real directionality now becomes focused forward – called beaming. If you’re sitting along that forward axis in front of the speaker, everything sounds great. But that’s unlikely – especially in the era of smart speakers, where everyone may be all over the place and the speaker may not occupy center stage on the entertainment console; it might be anywhere.
It’s for this reason that a standard old speaker has two or three cones and drivers in a cabinet. Each handles its own frequencies in a range that avoids beaming and breakup, with the added complication of having to minimize distortion as you move in frequency from one cone to the next. We’ve been doing this for a long time, under the assumption that it’s the only practical way to build a speaker.
Tectonic Audio Labs has been working on what they call Balanced-Mode Radiators, or BMR. They use a flat diaphragm instead of a cone. Which means, of course, that you get modes. Given an ideal, massless driver, you can get full decent sound out of such a setup. So why haven’t we done this? Because there are no such perfect drivers. A voice coil has mass, and it has to attach to the diaphragm in order to transfer the sound to it. And that’s the catch: the driver messes up the nice, neat modes and can again make things more directional.
Rather than reverting to a cone, they found that they can manipulate the nodes by placing rings at key spots around the diaphragm. This restores the original modes and brings the sound quality much closer to ideal. And it does so pretty much evenly almost to 180° across all audible frequencies.
(Image courtesy Tectonic Audio Labs)
They use these in two ways. For smaller speakers, they use BMR with a single central driver, playing with 3 or 4 modes. The diaphragm itself is made of doped paper with a doped honeycomb core. For larger speakers, they use the concept with a distributed-mode loudspeaker (DML), exciting dozens of modes on a diaphragm made of a unidirectional carbon fiber material with a Nomex honeycomb core.
Because of the size and intended power of these larger speakers, there is yet another challenge. In order to drive hard enough for the big leagues, you would normally need a very large driver in the middle.
So, instead of using a single driver, they use four “exciters.” Each one is smaller than one big one, and yet, together, they provide the needed power. They found that they could excite more modes by placing the exciters asymmetrically on the disk. They also experimented with “customizing” the signal for each exciter and found that it didn’t really have an impact. So all of them are driven alike.
Both BMR and the DML speakers share a bottom line: because of the clean frequency response across the range of human hearing, you can handle the whole range of frequencies with one diaphragm at all but the widest angles forward. No need for tweeters, midranges, and woofers.
Bringing it back to our more familiar domain, however, is the fact that this technology is not likely to be useful in a miniaturized MEMS format. That’s because, at that tiny scale, all of the modes are at frequencies above the audio range, so the whole problem being solved with BMR isn’t a problem. But, of course, you don’t get anywhere near the same sound power levels.
And that’s our audio roundup for today. I’m sure it’s not everything that happened, but I’ve tried to pick a few things that have interesting tidbits about them.
(Lead image courtesy Tectonic Audio Labs)
More info:
Sourcing credit:
Mike Polacek, President, Knowles
Michael Maia, VP of Ear and IoT, Knowles
Matt Crowley, CEO, Vesper MEMS
Tim Whitwell, VP Engineering, Tectonic Audio Labs



What do you think of these various audio announcements?