

I was just chatting with Mark Lippett, who is CEO at the British chip company XMOS. Mark was telling me that they recently announced the launch of their XVF3610 and XVF3615 voice processors. These little beauties will power the next generation of high-performance two-microphone voice interfaces for wireless speakers, TVs, set-top boxes, smart home appliances, gateway products, and more. We will be talking about these in greater detail in a moment, but first…
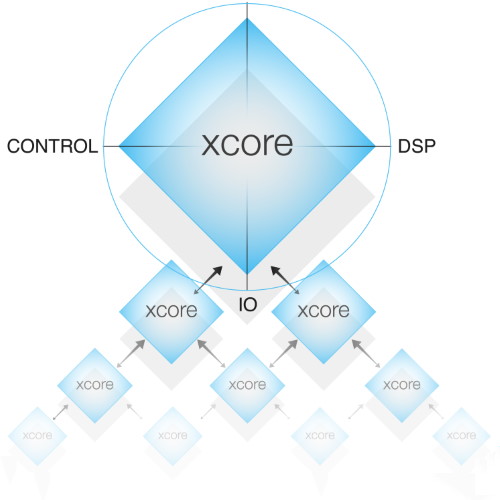
Let’s start by reminding ourselves that XMOS is a fabless semiconductor company whose claim-to-fame is their xCORE multicore microcontroller technology. These devices contain multiple processor “tiles” connected by a high-speed switch. Each of these processor tiles is a conventional RISC processor that can execute up to eight tasks concurrently. Tasks running on the same tile can communicate with each other via shared memory. Tasks can also communicate to other tasks running on the same tile or on other tiles over channels.
As I wrote in One Step Closer to Voice-Controlled Everything: “The xCORE architecture delivers, in hardware, many of the elements that are usually seen in a real-time operating system (RTOS). This includes the task scheduler, timers, I/O operations, and channel communication. By eliminating sources of timing uncertainty (interrupts, caches, buses, and other shared resources), xCORE devices can provide deterministic and predictable performance for many applications. A task can typically respond in nanoseconds to events such as external I/O or timers. This makes it possible to program xCORE devices to perform hard real-time tasks that would otherwise require dedicated hardware.”
Although not related to what we are talking about here, I can’t resist sharing two videos of XMOS-powered art installations created by the clever guys and gals at the London-based art collective and collaborative studio called Random International.
The first video shows one of Random’s Swarm Studies creations. This one is called Swarm Study / VII. As it says on YouTube: “Swarm Light invites us on a visual experience inspired by the study of a natural and fascinating phenomenon; the migratory patterns of thousands of birds.” Meanwhile, this portfolio entry on Random’s own website says: “Swarm Studies simulate patterns of group behavior seen in nature, embodying them in light. Inspired by the striking murmurations of starlings in flight, the myriad individual lights act collectively to create the swarm. Swarm Study / VII is a site-specific work for a Middle Eastern transport hub. Living within one, monolithic cube, the swarm behaves autonomously, creating an ethereal and meditative presence within its busy location.”
By comparison, the second video (which cannot, unfortunately, be embedded here, but happily the link does work) implements something that I think may be a dream shared by many of us — the ability to walk through pouring rain without getting wet. Did you ever read the books in the The Earthsea Trilogy — by American writer Ursula K. Le Guin (following the addition of more books after an 18-year hiatus, these are now collectively known as The Earthsea Cycle)? These stories are set in the fictional archipelago of Earthsea where magic is a part of life (although only few have the talent to practice it) and centers on a young mage named Ged. The idea is that words have power, and if you know the words that were associated with things at their creation, then you can control them. Suffice it to say that Ged could certainly take a stroll in a rainstorm without becoming even slightly damp.
The point of all this is that, in this second video, we see Random’s Rain Room, which was first shown at the Barbican, London (2012); followed by the MoMA, New York (2013); the Yuz Museum, Shanghai (2015), and the LACMA, Los Angeles (2015–2017), before ending up at its current installation in Sharjah, United Arab Emirates. The Rain Room allows visitors to the installation to walk through a downpour without getting wet. Motion sensors detect the visitors’ movements as they navigate through the darkened space, becoming “performers in this intersection of art, technology, and nature.”
I don’t know about you, but I would love to be able to take a walk through this Rain Room artifact to get a feel as to what it would be like to be able to wield this sort of magic. Returning to the topic at hand, however, both of these exhibits demonstrate the computational power and lightning-fast responsiveness of chips based on the xCORE architecture.
I fear I may be in danger of wandering out into the weeds a little, so let’s rein ourselves in. A brief summary of the history of XMOS is as follows. Founded in 1978, a British semiconductor company called Inmos developed an innovative microprocessor architecture intended for parallel processing called the Transputer. In April 1989, Inmos was sold to SGS-Thomson (now STMicroelectronics). The reason I mention this here is that XMOS was founded in 2005, where the name XMOS is a loose reference to Inmos, and some of the concepts found in XMOS technology (such as channels and threads) are part of the Transputer legacy.
In 2008, XMOS shipped its first xCORE chip, which found use in a wide variety of embedded applications. In 2010, XMOS extended its footprint into the multi-channel audio market. In 2014, the folks at XMOS collaborated with a client to adapt the XMOS array microphone to a voice application. In 2017, XMOS secured an industry first with Amazon Alexa Voice Service qualification for a far-field voice interface with a linear microphone array.
By now, we are used to microphone arrays such as those sported by the Amazon Echo with seven microphones (six in a circle and one in the middle). The thing is that this form of array is not cheap. It’s great for specialized high-end devices like smart speakers, but it’s too expensive to be deployed in cost-conscious applications like TVs, set-top boxes, smart home appliances, and gateway products.
When you come to think about it, we humans manage to identify the source of a voice and recognize what is being said using only two ears. Of course, this is because of the massive amount of processing capability provided by our biological brains (take that, Spot the dog!). This explains why, in 2017, XMOS acquired SETEM, a company that specializes in audio algorithms for source separation. Two years later, in 2019, the guys and gals at XMOS disrupted the market when they launched a high-performance 2-microphone solution, costing less than a dollar, targeted at the smart device market. More recently, in 2020, the chaps and chapesses at XMOS introduced their latest and greatest xCORE.ai architecture, which provides a fast, flexible, and economical platform for the AIoT*, delivering high-performance AI, DSP, IO, and Control functionality in a single device (*see also What the FAQ are the IoT, IIoT, IoHT, and AIoT?).
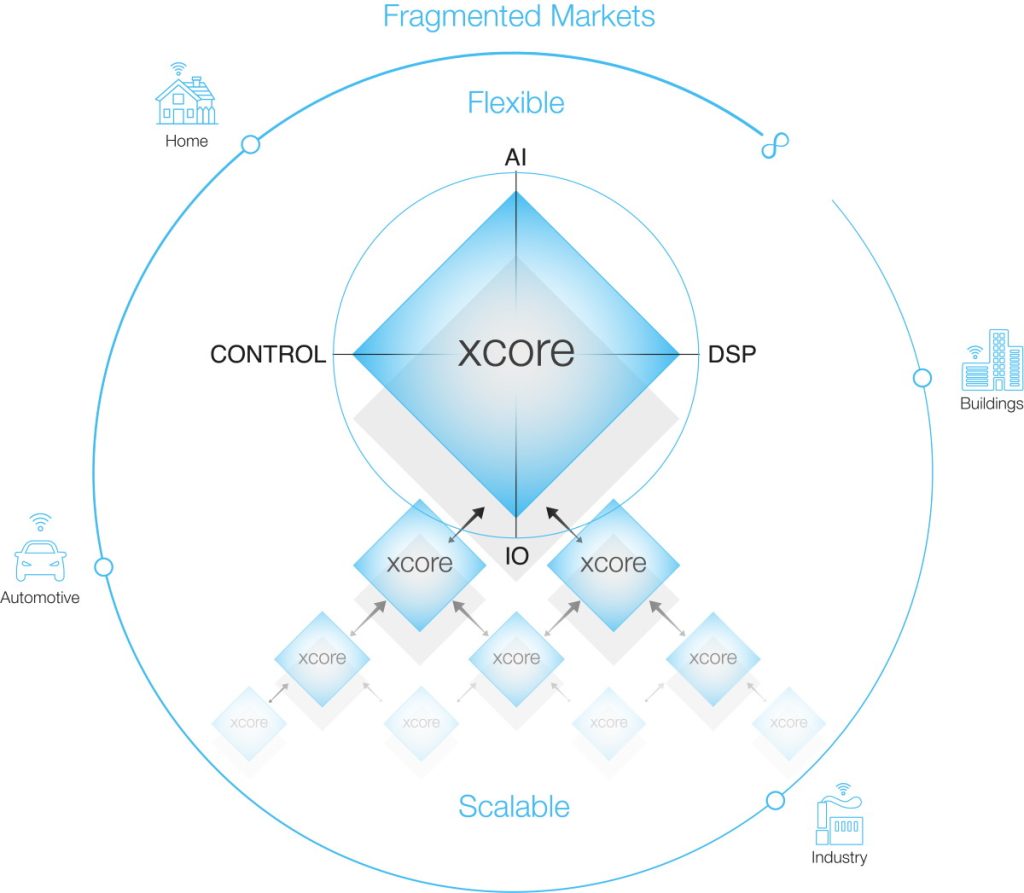
xCORE devices provide ideal solutions to address the extreme computer requirements of today’s fragmented markets (Image source: XMOS)
Now let’s look at things from a slightly different perspective. When XMOS entered the USB audio market, they soon became recognized as the go-to specialists with regard to providing fully functional reference designs. These were designs users could take, “wrap plastic around them,” and deliver them as part of a product. Alternatively, users could deconstruct these reference designs and modify them to add their own “secret squirrel sauce” so as to differentiate themselves.
Later, when XMOS entered “voice space” (where — paradoxically — no one can hear you scream), they did so with their second generation xCORE 200 devices. Fulfilling the demands of far field speech detection and recognition left the xCORE 200 pretty much full, with no room left over for customer modification, optimization, and differentiation, so the folks at XMOS opted to create voice solutions that looked like application-specific standard products (ASSPs) under the banner of VocalFusion (VF). These devices, like the XVF3510, are off-the-shelf voice processors that users can simply lay down on a board and then configure them as required by means of an application programming interface (API).
As was previously mentioned, the latest and greatest xCORE.ai architecture was introduced in 2020, These devices have a lot more compute power and a lot more resources. In turn, this means that the folks at XMOS can pivot once again — using xCOR.ai chips to augment their fixed voice solutions with configurable voice platforms like their newly introduced XVF3610 and XVF3615 voice processors.
These designs mark an evolution of the XVF3510 voice processor already used within Amazon Alexa systems, and they provide powerful audio echo cancellation (AEC) and interference cancellation algorithms to suppress noise from dominant sources and enable cross-room barge-in. The XVF3610 and XVF3615 also include automatic audio reference delay calibration — a critical capability for voice-enabled TV systems — expanding the range of devices and environments where voice interfaces can be implemented.
Furthermore, the XVF3615 adds embedded Amazon wake word for single-pass Alexa enabled systems, allowing manufacturers to offload wake word processing from their host processor/SoC systems. (The XVF3610 is now available in distribution, while the XVF3615 will be available in distribution in January 2022.)
There are also two development kits to help us evaluate the XVF3610 and prototype our voice-enabled products — one for USB plugin accessory implementations (with a USB Control Interface) and another for built-in voice implementations (with an I2C Control Interface).

XK-VOICE-L71 Development kit for the XVF3610 (Image source: XMOS).
The XVF3615’s wake word detection capability is of particular interest. If the host processor/SoC has to perform wake word detection itself, then it sits there hour-after-hour, day-after-day, listening for the wake word while consuming 4 watts of power. By comparison, the XVF3615’s wake word detection capability consumes only a few hundred milliwatts. When the XVF3615 detects the wake word, it wakes the host processor/SoC.
The XVF3615’s wake word detection is of sufficiently high-quality that it does not need to be re-affirmed by the host processor/SoC. This is awesome just the way it is, and I can easily see solutions appearing based on the combination of the XVF3615 and a host processor/SoC, but wait, there’s more…
All of this reminds me of two columns I penned here on EEJournal: A Brave New World of Analog Artificial Neural Networks (AANNs) and Aspinity’s Awesome Analog Artificial Neural Networks (AANNs). The problem with a system waiting for a wake word is that the world is full of ambient sounds — dogs barking, cats barfing (I speak from experience), birds chirping, systems “binging” inside the house, cars and trucks rumbling by outside the house, wind, thunder, rain… the list goes on.
Even if we off-load the wake word detection from the host processor/SoC (that consumes 4 watts) to the XVF3615, we’re still going to be consuming a couple of hundred milliwatts. This may not seem like much, but when we eventually have billions upon billions of voice-controlled devices, we’re talking about using the output from multiple power stations just to determine if anyone is talking.
A more elegant solution would be for the XVF3615 to also be put to sleep, and for Aspinity’s always-on Reconfigurable Analog Modular Processor (RAMP) to listen to every sound using its analog AI/ML neural network to determine if that sound is human speech, doing all this while consuming only 25 microamps (µA) of power. As soon as the RAMP detects human speech, it wakes the higher-power wake word processor — the XVF3615 in this case.
Now, this is the clever bit (well, one of the clever bits). The RAMP chip constantly records and stores (in compressed form) the pre-roll. When it detects human speech and wakes the wake word processor, it un-compresses the pre-roll and feeds it to the wake word processor with the live audio stitched onto the back. This means that it’s only when someone is talking that the XVF3615 wakes up and starts to listen for the wake word. If the person stops talking without saying the wake word, the XVF3615 goes back to sleep. However, if the XVF3615 detects the wake word, it wakes up the host processor/SoC. Brilliant!
Wow! I’m afraid I got a little carried away with excitement there, but — to be fair to myself — I think this is pretty exciting. What about you? What do you think about all of this?

