May the odds be ever in your favor. – The Hunger Games
Intel announced the name of its IA-64 processor in October, 1999. The company’s future 64-bit, VLIW processor would be known as the “Itanium.” Overnight, Usenet boffins christened it the “Itanic,” and the name stuck. The Register has long used the name, and my friend Nick Tredennick often used the term at Microprocessor Forums. Understandably, Intel was not enamored of the nickname.
That was two decades ago, and the Itanium has been sinking for at least that long. (See “Intel Pulls the Plug on Itanium: Possibly the World’s Most Expensive Failed Chip Project.”) On January 30, Intel issued a Product Change Notification (# 116733 – 00) that effectively said, “It’s still sinking.” The notification informs Intel’s customers that the final order date for Itanium 9700 series processors is January 20, 2020 and that final Itanium processor shipments will take place no later than July 21, 2021. Essentially, this notice affects only HPE, which has said that it will continue to support its Itanium-based servers until 2025.
Tick, tock. Tick, tock.
The Itanium project traces its roots back to HP’s PA-RISC efforts of the 1980s and 1990s. The “PA” in PA-RISC means “Precision Architecture,” and the “RISC” – well, that stands for “Reduced Instruction Set Computer,” as it does for every other RISC processor out there. HP introduced the first PA-RISC processors way back in 1986 and continued to develop bigger, better, faster PA-RISC iterations over the next decade. By 1996, the PA-RISC ISA had jumped to 64 bits in the PA-8000 (Onyx) processor.
HP’s successor to the PA-RISC endeavor was to be the EPIC (Explicitly Parallel Instruction Computing) processor. It was a 128-bit, VLIW architecture. HP has a long history of love affairs with out-of-the-ordinary processor architectures. For example, in the 1970s and 1980s, during the days of the HP 3000, the love affair was with stack-based architectures.
As the EPIC journey was ramping up, HP management was beginning to understand that proprietary processor development was getting increasingly expensive. So HP went looking for an EPIC development partner. They found Intel, which has had its own love affairs with oddball architectures (the iAPX 432 “Advanced Performance Architecture” and the i860 RISC processor, to name just two). These two lovers of eccentric processor architectures, HP and Intel, partnered in 1994 to develop the IA-64 architecture, which would be derived from HP’s EPIC work.
Boldly, Intel and HP predicted that the IA-64 would dominate in servers, workstations, and high-end desktops. Based on the hoopla, Compaq and Silicon Graphics decided to abandon further development of their respective Alpha and MIPS microprocessor architectures and instead made plans to immigrate to the promised land of IA-64.
HP and Intel also predicted that the IA-64 architecture would eventually supplant RISC and CISC architectures for all general-purpose applications.
Didn’t happen.
First, just getting the thing designed and working was a huge task – much larger than expected. By 1997, it was apparent that the IA-64 architecture and the companion compiler were going to be much more difficult to implement than originally thought. The delivery timeframe of Merced began slipping. The first Itanium was late. Delivery slipped into the new millennium.
Second, Itanium’s VLIW compiler wasn’t going to be and would never become a fully realized goal. It turned out to be a lot harder than expected to hammer a random set of applications into optimal sets of VLIW instructions.
Last March, I wrote an EEJournal article titled “Fifty (or Sixty) Years of Processor Development…for This?” that discussed a talk by the noted microprocessor expert Dr. David Patterson, who literally wrote the book on microprocessors (Computer Architecture: A Quantitative Approach). During that talk, Patterson discussed the difficulties of working with a VLIW architecture:
- Branches are unpredictable, which complicates scheduling and packing parallel operations into VLIW instruction words.
- Unpredictable cache misses slow execution and create variable execution latency.
- VLIW ISAs explode code size.
- Good optimizing compilers for VLIW machines turn out to be too difficult to create.
Patterson also quoted Donald Knuth, perhaps the world’s best known computer algorithm wizard, who observed, “The Itanium approach…was supposed to be so terrific – until it turned out that the wished-for compilers were basically impossible to write.”
Compilers just do better with simple, RISC-like architectures.
In addition, our everyday use model for computers was changing radically at around the same time. In the first 20 years of PC use, we operated most PCs as single-tasking machines, so making single-threaded code run faster was the priority. However, with the Internet revolution came massive multitasking in the form of multiple open windows running applications that handled multiple multimedia streams. At the same time, server processors were handling the same sort of multitasking loads, only more so.
The object was to make all of these simultaneous tasks run faster. That goal pointed the way to putting multiple processors into server processors and even into personal computers. As Jerry Pournelle liked to write in Byte magazine many decades ago, “One person, at least one CPU.” This rule became known as “Pournelle’s First Law, amended.” (Pournelle passed on in 2017. His first statement of his first law was “One person, one CPU,” but that was very early in the microprocessor revolution, when most users didn’t yet have a CPU, so it was a revolutionary idea then. Not so much now.)
Something else, perhaps unforeseen, also happened to reinforce Pournelle’s First Law. Thanks to the extended continuation of Moore’s Law, we started making multiprocessor chips and manyprocessor chips, and we’ve endowed each processor with hyperthreading so that each processor chip can run many simultaneous threads with no changes needed for the software running in each thread. Contrast this with the need to recompile everything for Itanium. The end result was predictable.
In fact, Nick Tredennick predicted the outcome in a Microprocessor Report article published way back in 1994:
“I used to get compliments from Intel employees who read my opinions. Others wondered if I secretly worked for Intel. This opinion should end the compliments and the speculation. Intel has done something so dumb even I noticed. Intel and HP have shot each other in the foot with the announcement that they will merge x86 and PA-RISC into a common architecture that Microprocessor Report calls P86.”
He reprised his prediction, also in a 1999 Microprocessor Report article:
“Canceling the project now would be a public-relations mess, given the number of public commitments Intel has made. But we do not expect end users to line up for Merced. Intel and the IA-64 system vendors will put on a happy face when discussing Merced. If buyers ask about performance, Intel will talk about McKinley. This positioning will probably work—at least until McKinley’s engineers figure out the Actual Performance of their design.”
(Note: Merced and McKinley were the first- and second-generation versions of the Itanium VLIW processor.)
Many things have changed in the ensuing two decades. Compaq and Silicon Graphics are gone. HP acquired Compaq during the reign of Empress Carly. The HP board of directors deposed Carly a little while later. Meanwhile, Silicon Graphics went bankrupt (a second time), and its remains were purchased by Rackable Systems, which then turned right around and renamed itself Silicon Graphics International (SGI). HP splintered twice, and one of the fragments, HPE, ended up buying SGI. All of these outcomes have more gravitas than the slow-motion train wreck that is the Itanium processor.
At this point, the only company that really cares about Itanium is HPE, which amusingly puts the Itanium into its line of Integrity servers.
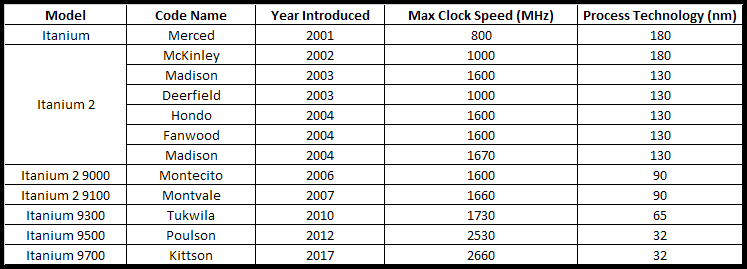
I take no glee in reporting the continued and agonizingly slow demise of the Itanium processor. Despite all of the criticism, it was a very noble project. If you look at the number of Itanium processors developed (see table below) and multiply it by the number of person-hours you need to develop one microprocessor chip, the resources expended on the Itanium project as a whole staggers the mind.
Itanium’s developers sought a path to much faster processing. Unfortunately, the theory behind Itanium’s development was just plain wrong. While VLIW architectures do appear to work well for specialty processors running well-behaved code, particularly DSPs, they’re just not appropriate for general-purpose applications thrown willy-nilly at server processors.
And so, we remember the fallen.