


We’ve looked at a number of architectures for accelerating neural-network inference calculations before. As an example, those we saw from Hot Chips were big, beefy processing units best targeted at cloud-based inference. But, as we’ve mentioned, there is lots of energy going into the development of inference engines that would work at the edge, with more modest power and performance expectations.
And, regardless of architecture or where they’re deployed, everyone is trying to be more efficient about whatever performance they manage to achieve. One approach to this is to raise the level of abstraction.
Moving Up to Graphs
The whole job of AI development tools is to take an inference model and reduce it to something that the target engine can execute. For the most part, today that reduction leads to a series of raw computations, with lots of multiply-accumulates (MACs) for handling the multiplication of activation vectors and weight matrices to generate new activation vectors.
So the job has been to take a neural network, which can be represented as a graph, and generate all of the calculations that will happen to generate an inference result. That’s likely to be millions or billions (or more) of calculations for a serious network.
So it’s possible for a compiler to methodically work through the network and, for each node, generate a list of the computations it has to do. Store all of those as a program, along with the appropriate control, and you have a way to execute the inference.
But some companies working on newer architectures believe that taking this graph and reducing it all the way to its constituent calculations results in the loss of useful information. Those low-level calculations no longer reflect the structure of the graph, which explicitly shows what came from where. They’re simply MAC (and other) calculations done in a way to give a correct result.
Remaining at the higher, abstract level, according to this newer approach, maintains knowledge about which nodes are feeding which, and that knowledge can be leveraged. It gives better specificity as to which calculations depend on which, and that information can influence scheduling in a way that reduces the amount of internal memory needed.
Today we talk about two different ways of approaching that problem: one by Blaize, who executed their launch just a couple of months ago, and Mythic, whom we’ve already talked about in our discussion of in-memory computing. They both do what they refer to as streaming graph processing. (We’ll discuss the streaming part in a minute). We’ll take these two in order. Both architectures use internal tiles that are replicated into a grid; we’ll focus on what’s in the tiles. There’s lots of detail that we won’t get into.
Blaize
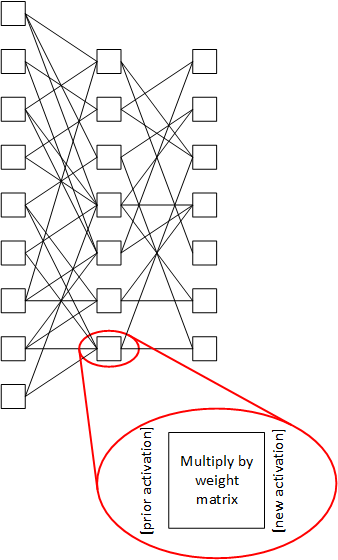
Blaize* uses a few images to help illustrate graph processing and the benefits of streaming. A traditional non-streaming neural network is shown below, with nodes labeled using letters. The activations are stored in memory blocks (labelled using numbers), multiplied by the weights, and then stored in working memory (or back out in DRAM) for use by the next node that needs them. In these traditional architectures, the nodes are all calculated in full, with each node completing before another node can start. For instance, Node A executes, creating activation blocks 1 and 2. The timeline at the bottom shows that 1 and 2 are created in parallel. Block 1 is then used for node B; 2 is used for node C.
(Image courtesy Blaize)
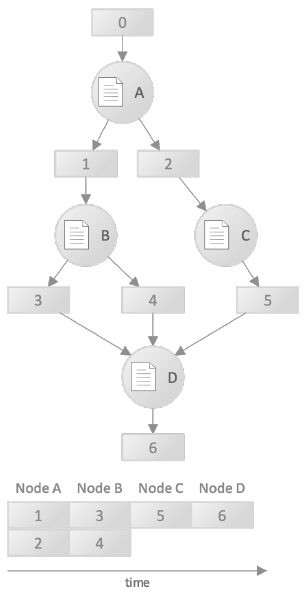
Because each node is calculated in full, memory must be available for the entire set of generated activations. By moving to a streaming approach, then, as soon as the first data in block 1 is available, node B can start executing. If that happens, then Node B is likely to consume the first data created by A, freeing up that space for reuse, before A completes. For that reason, much less activation storage is required – you never have to store the entire set of A’s output activations at the same time. They illustrate this with the following diagram.
(Image courtesy Blaize)
You’ll see that the numbered memory blocks are much thinner and that the timeline has much more parallelism because B can start computing before A finishes. This gives them task-level parallelism, which they claim to provide uniquely. As they describe it, other architectures have lower levels of parallelism: thread-level, data-level, and instruction-level – which Blaize also provides.
This reminds me of the communications distinction between store-and-forward and cut-through. The traditional approach stores the entire set of activations before doing the next thing, which is like storing an entire packet before forwarding it on. The Blaize approach starts early, just as cut-through delivery starts sending a packet on before it’s been completely received.
But how does the system know which data is needed by which node? This is where the graph orientation comes in. At compile time, the tools keep some information about the structure of the graph – including dependencies. Those are saved and loaded into the device as a “meta-map.”
The architecture includes a hardware scheduler that can schedule tasks in 1 cycle. Based on the meta-map, it then schedules which node computations will execute when and where – that is, on which tile. That explicit scheduling happens dynamically, in real time. The weights themselves still must be stored and moved into place.
They claim that, to their knowledge, they have the only architecture that uses this “streaming” capability to consume newly produced data as soon as it’s available in order to reduce the need for storage. We’ll review this after discussing Mythic.
I also asked about neural nets that involve feedback, like RNNs. The architecture is set up to process directed acyclic graphs, or DAGs. That “acyclic” thing means no feedback. They noted that many of the applications using feedback – time-based ones like speech recognition – are moving away from using feedback so that the resulting graphs will be acyclic. That aside, their CTO says that the cycles can be “unrolled with no impact” to run in their architecture.
Note that Blaize’s architecture, consisting as it does of general compute elements boosted by this streaming thing, can be used for more than just neural-net processing. If, for example, a computer vision application included a CNN between some pre-processing and post-processing steps, the pre- and post-processing as well as the CNN could be done in a single device, space permitting.
Mythic
We looked at Mythic’s in-memory computing (or compute-in-memory – you’ll see both terms used) already, with their analog flash memory providing MAC calculations where the weights are stored. Here we put this capability into an architectural perspective. And the compute-in-memory thing is different enough to where this stuff takes a bit of rethinking.
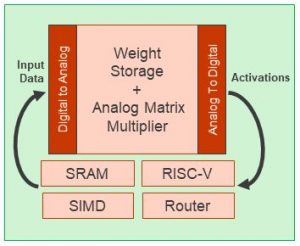
Most neural-net processing tiles from other companies – including Blaize – feature a fast compute engine at the heart of the tile. Mythic’s tile features the analog memory array. It has some digital computing capabilities, but the heart of the matter is the matrix multiplication, and that’s done by the memory. An entire node can be processed in one memory “access.”
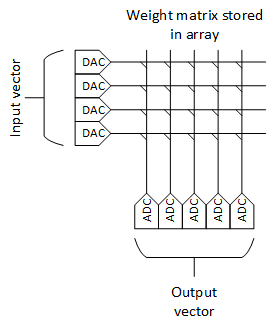
Each tile has a 1000×1000 flash array. While other architectures tend to think node-by-node, these guys appear to think layer-by-layer. That’s because the nodes themselves don’t exist in isolation: they’re packed into the memory.
A single MAC calculation comes from setting the word lines to their analog values (more than one word line at a time, unlike normal memory) using DACs and then measuring the cumulative current at the bottom of a bit line. You would use as many columns as needed to match the output activation width. So by measuring all of the columns associated with one node after one access, you have the desired output activation vector.
With 1000 word lines, you could process a node having 1000 inputs. But, more likely, you’re going to pack more than one node onto each set of columns. This would add some efficiency, but it would also require some careful bookkeeping. Bear in mind that the calculation consists of measuring the current contributed by active word lines along the bit line. If there were more than one node on a column, then you would want to execute only one node at a time – meaning that the inputs (i.e., word lines) associated with another node would need to be suppressed so that they didn’t contribute any current. That would suggest that the deactivated nodes on the column would be most efficiently handled if they were for nodes that would be calculated at different times. Otherwise, what might have been a parallel computation becomes a sequential one.
(Image courtesy Mythic, Inc.)
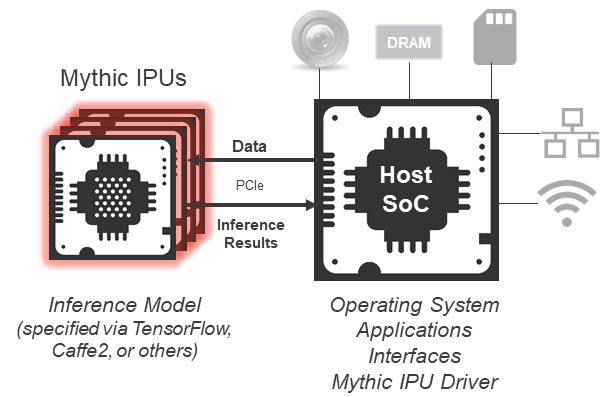
So it’s possible to allocate the word lines and the columns to create the output activation vectors for, presumably, a set of non-concurrent nodes. That’s for the array within a single tile. In fact, a serious application will require more than one tile – and the first chip has 108 tiles. The tiles can communicate via a network-on-chip (NoC) – and multiple chips can intercommunicate via PCIe as well.
(Image courtesy Mythic, Inc.)
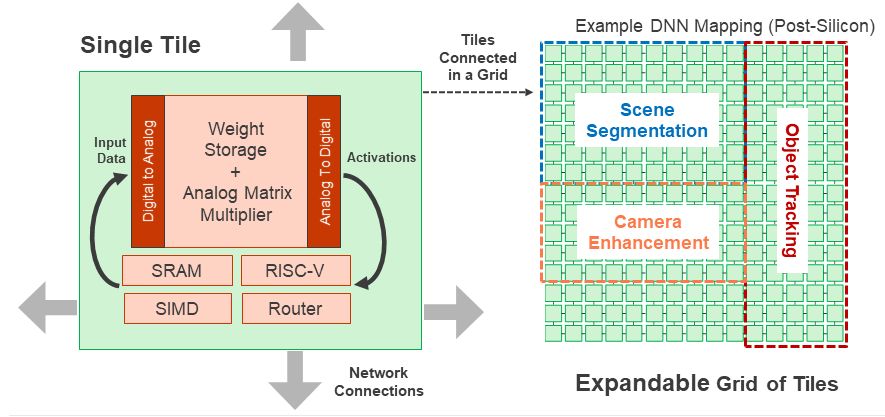
Realistically, the tile array in a sophisticated application would likely end up being allocated to different models. That allocation could also take into account potential parallelism.
(Image courtesy Mythic, Inc.)
To be clear, however, all of this allocation and placement is done by the tools. It’s not a manual operation. And because the locus of computing for all parts of the network is established by the arrays and their contents, this can all be figured out deterministically – and statically – by the tools ahead of time. No dynamic scheduling is required.
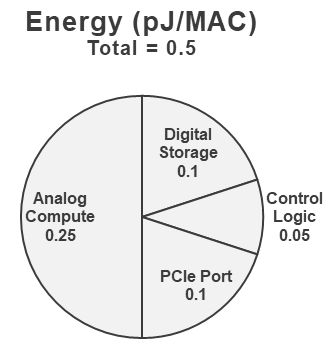
Here’s the crux of their point: the weights are the biggest data-moving burden. If you have activations that are 1000 wide, then you have 1,000,000 weights. It’s much easier to store and move the activations than the weights. So weights are stored in the flash – permanently. There’s no need to move weights around at all; the entire array pre-loads the weights, since the weights for a given model are static. Because flash is non-volatile, this is needed only once (and when updating). During operation, only the activations are moved, since they’re dynamically created. By not moving weights, they save a lot of energy. Their energy breakdown is shown below, adding to a total of 0.5 pJ/MAC.
(Image courtesy Mythic, Inc.)
There are, of course, other things in that tile besides the memory array – and other things that will be needed when calculating an inference. One common requirement is to add some non-linearity to output vectors using sigmoids, ReLU functions, or something similar. Mythic says that they perform the non-linearity function in the ADC, so that no other explicit computing is required for that. Meanwhile, pooling is also common – and that’s handled by the SIMD. The RISC-V processor is largely for control.
Streaming Nuances
Mythic claims to support streaming as does Blaize, although it’s hard to compare to the Blaize architecture, since they’re so very different from each other. The main difference is that Mythic manages the streaming at compile time, while Blaize uses compiled information to stream at run time. But, if you think about it, there’s a big difference between how these two architectures stream.
With Blaize, the tiles can be used for multiple nodes, as scheduled by the hardware scheduler. With Mythic, the entire network is represented statically in the memories. So Blaize must literally store activations in working memory so that they can then be moved to the tile that’s scheduled to do the next node. Because the Mythic setup is static, as soon as an activation vector is created, it can be – actually, it must be – routed on to the next array that will work with that vector. In other words, the vectors may not need to be accumulated anywhere in working memory.
All of that said, the Blaize architecture would also work more efficiently for true streaming applications – like video – if the tiles were at the very least pre-assigned to nodes, even if their operation would still need to be scheduled. If the tiles are reused for different nodes, then you have to wait until one set of inferences – one frame, for example – is completely done so that you know that the tiles are all free to be reassigned and start over. If no reassignment is done – if it’s literally just a scheduling question – then, as soon as, say, layer 1 of frame 1 is done and layer 2 is starting, then layer 1 of frame 2 can start. As far as I can tell, the Mythic architecture works this way natively.
The other benefit to static tile/node assignment is that weights need to be loaded only once. With the Blaize architecture, the weights would be loaded at each power-up and remain in place, without needing to be moved. All of this said, the Blaize materials are vague about the number of tiles available on their SoC; it’s unclear as to how many nodes can be resident at any one time. If ResNet50 – not leading edge – has 50 layers, then you can see that a fair number of tiles would be needed for static assignment.
Design Tools, Applications, and Product Plans
We’ve talked about the basics of both tool sets for compiling a graph. But the tools are used for much more than that. They’re needed for the overall conversion of a trained network into an inference engine.
Blaize says that they can interact with the training framework to “train to utility” – thus avoiding retraining later. Their NetDeploy tool will also automatically do node pruning and fusing while keeping to a given level of required accuracy.
Mythic is working on a similar toolset, although they haven’t completed quite the same level of automation; such automation is on their roadmap. One particular note: the flash cells each can store an 8-bit value. In other words, this is a 256-level flash cell. For that reason, it’s easiest to quantize to 8 bits, since that fits natively with the array precision.
Mythic also has – and needs – no floating-point support, while Blaize does support floating point. And one note to point out: in their early chips, Mythic isn’t using a DAC at the array inputs, but rather a digital approximation circuit. This will eventually be replaced by true DACs. I asked whether the first commercial versions (as opposed to test chips) would have DACs or digital approximation, but they declined to provide that detail.
As to applications – well, every company focuses on something. Blaize is looking at vision, automotive, and enterprise – no big surprise. That said, they don’t see the black-and-white edge-vs-cloud differentiation that we usually see. Instead, they see a continuum of possible places where AI could be executed. Each farther-away location will have more compute power, presumably, but going farther away will also introduce higher latency. This spectrum, if it materializes, will provide more choices in balancing compute power against latency.
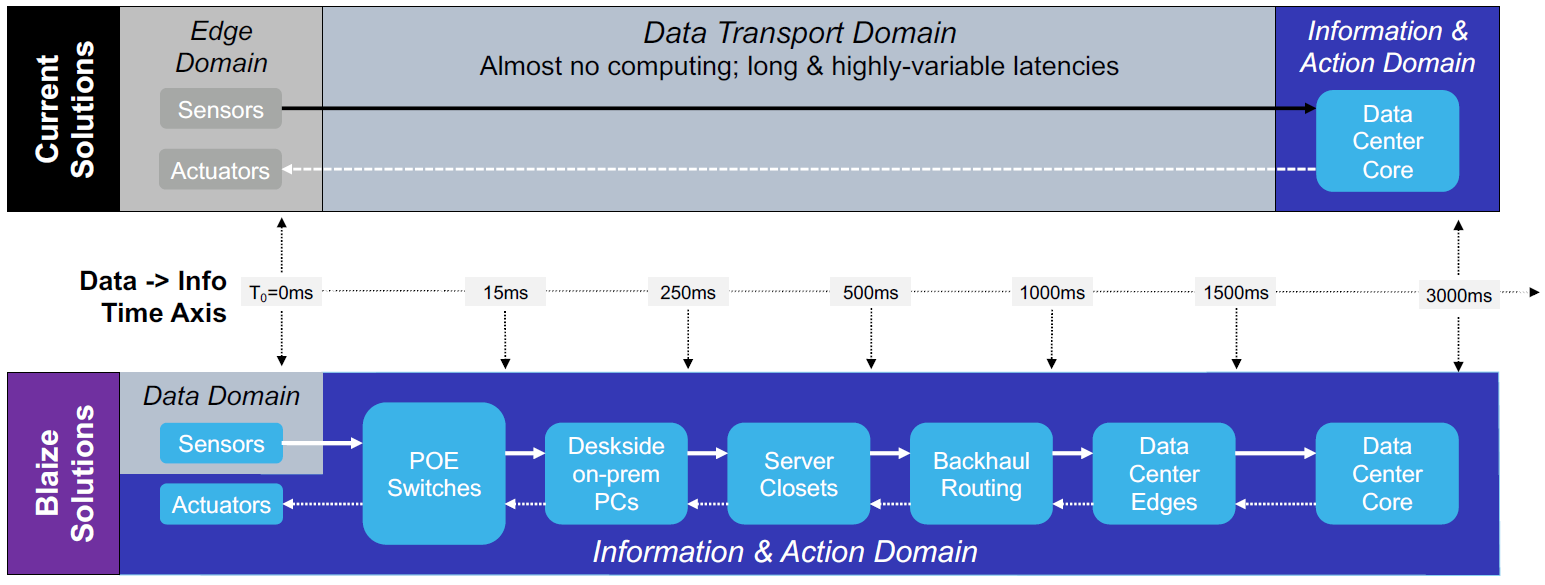
(Click to enlarge. Image courtesy Blaize)
As to products, Blaize is not planning to sell individual chips except by special arrangement. Instead, they’ve built a PCIe board that can be plugged directly into a server in a manner that’s ready to be used by data jockeys. They’re even making available a server preloaded with all of the tools and accelerator for a turnkey system for early access to “qualified customers.”
Mythic’s product strategy is less clear at the moment, since they’ve announced their technology, but not their specific products. They’re launching in 2020, so we should know more soon. They did say that they’re aiming both for data-center and for some edge applications – most likely those that are line-powered, like security cameras. At present, they’re not targeting battery-powered applications at the milliwatt level.
And that’s it for now on these guys. There’s so much more stuff lying on the cutting-room floor that simply wouldn’t fit, but I wanted to focus on the high-level capabilities and differences. We can talk about other aspects later, if compelling stories arise. You can find some more details at the links below.
*If you’ve been keeping up with this stuff, you may be familiar with Blaize under the name Thinci (pronounced “think-eye”). They changed their name with their launch.
More info:
Sourcing credit:
Richard Terrill, VP of Strategic Business Development, Blaize
Rajesh Anantharaman, Director Products, Blaize
Linda Prosser, Sr. Director, Corporate Marketing, Blaize
Mike Henry, Founder, Mythic
Tim Vehling, SVP Product and Business Development, Mythic



What do you think of these graph-based AI inference accelerators from Blaize and Mythic?