


Not long ago, we published a piece describing Cadence’s new Tensilica Vision C5 processor. We used the opportunity to give a brief primer on convolutional neural nets (CNNs) and their role in vision processing. In fact, if you want a quick CNN refresher, I’d encourage you to go back to that.
In ironic timing (at the risk of reviving the argument over what “ironic” really means), right when that was going to press, I talked with Synopsys at DAC about their new vision solution. And it builds nicely on the prior story.
Let’s go back to one of the early concepts in the prior piece. It was about the fact that, prior to this, CNNs were typically accelerated by using dedicated blocks specifically to handle the convolution, since convolution is a computationally intensive operation. You might simplistically view this as the following:
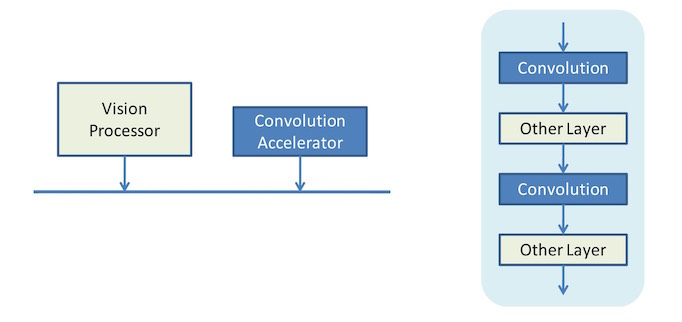
What we’re seeing here is a CNN on the right (highly simplified) as implemented by this older approach. The vision processor in this case hands convolution off to an accelerator attached to the bus, handling all of the other operations itself. This processor could be a DSP or GPU or CPU or some combination of them, at least in theory. The colors on the layers of the CNN on the right indicate which ones are processed by which block.
The challenge here is that you’ve got time-consuming handoff operations as the processor delegates to the accelerator across the bus. What Cadence discussed with their C5 processor was a CNN engine that, in a single IP block, could handle an entire CNN without going back and forth across the bus to get the job done. I simplistically illustrate this as follows:
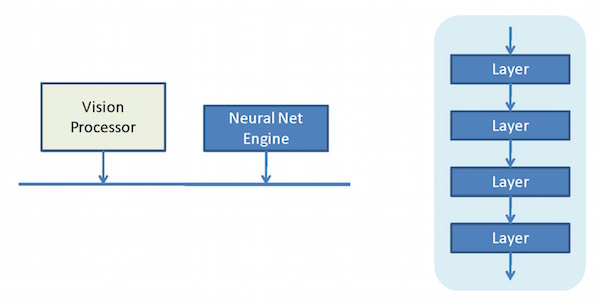
This looks almost the same as the prior figure, but the convolution accelerator is replaced by an engine that can handle the full CNN, as indicated by all layers now being blue on the right. This tightens up the interaction between convolutional and non-convolutional computations within the CNN. For Cadence, the Vision C5 would sit alongside the Vision P6, and, together, they’d get the job done – presumably more efficiently than would an accelerator-based design.
Well, Synopsys says they’ve taken that integration one level further, bringing the vision processor and the CNN engine together in one block. So, roughly speaking, that would look something like this:
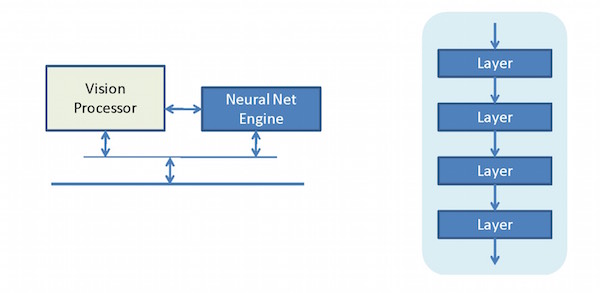
It reflects yet closer coupling between the CNN engine and the processor that will do all the non-CNN stuff. So we started with a solution that has the processor doing everything except actual convolution, and from that we moved to a solution where the processor can offload the entire CNN to another block, and thence to a block bringing it all together without needing to jockey back and forth across the main bus.
More specifically, the Synopsys EV6x block has an architecture that looks as follows.
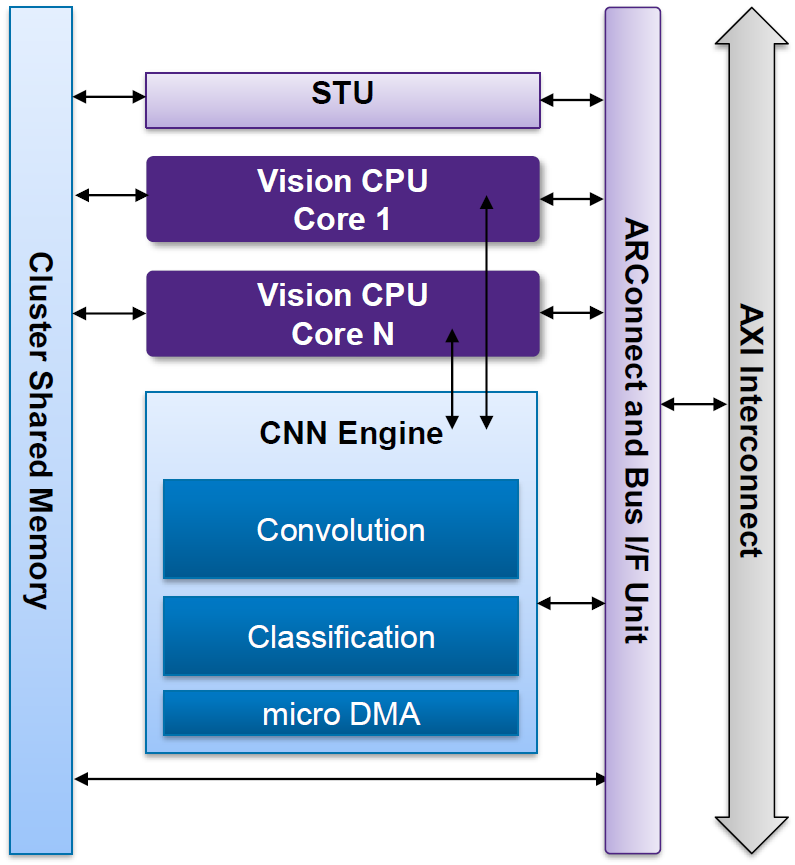
Image courtesy Synopsys
That STU thing is a Streaming Transfer Unit, providing low-overhead DMA services between the internal bus (and, from there, potentially all the way out to the system bus) and the memory shared by the cluster. This echoes the Cadence dual-port ping-pong approach, where one block would be the working block while another was being loaded. But here, the loading is done by a separate unit with its own interface.
Of course, this integration doesn’t much matter if it doesn’t improve performance. Synopsys is claiming up to 4.5 TMAC/s, implemented on a 16-nm node (since this is, of course, IP).
There’s a bit more behind that performance story. Obviously, speed depends on how much work you have to do, and how much work you have to do depends partly on the data precision you’re using. Ideally, we’d be doing 32-bit floating-point calculations, but we’re talking small embedded devices here; fixed-point is preferable.
Within that fixed-point domain. Cadence can do 8-bit (1 TMAC/s) or 16-bit (512 GMAC/s), again, at 16 nm. But Synopsys has data showing that 8 bits can result in too many recognition errors, while 16 bits may be overkill.
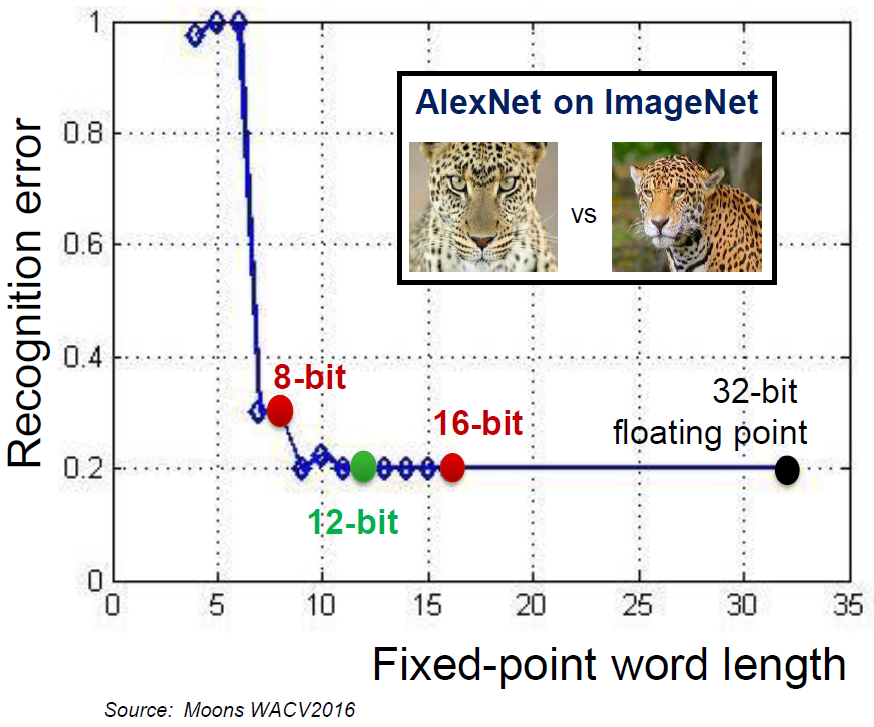
Image courtesy Synopsys
12 bits, according to this data, provides good results for less power and area. Synopsys says that a 12-bit multiplier is just over half the size of a 16-bit version, and, with all the multiplication going on, that can add up. They have, therefore, gone with a 12-bit solution (although they can handle CNNs trained for 8-bit engines). They claim power efficiency of 2 TMAC/s/W.
The full EV6x IP block is shown below.
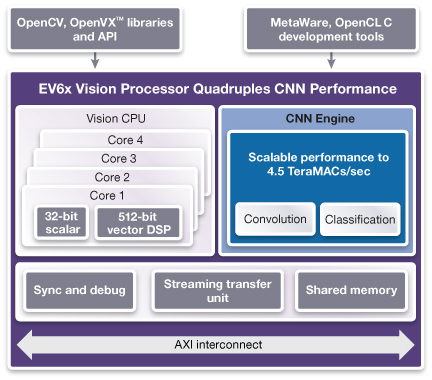
Image courtesy Synopsys
Graphs Within Graphs
When discussing how designs actually get done, terms like “graph” get tossed about in a manner that, unless you’re in the thick of this stuff, might be confusing. I certainly got confused, and Synopsys’s Pierre Paulin helped me to unpack what’s going on. This really gets to the design flow for a vision application.
Much of the discussion revolves around the CNN per se. But there’s lots more to a full-on design than just the CNN. The processing of images can be expressed as a dataflow graph, represented, amongst other options, using an open-source format, OpenVX. Each node in the graph will represent a task of some sort. Some might be CNN-related, but not necessarily others. You may have some filtering to do, noise reduction, color conversion, region-of-interest isolation – any number of such functions that don’t involve a CNN. Eventually, the data might be delivered to a CNN for image content classification.
Each of those nodes requires an implementation. Let’s hold off on the CNN nodes for a minute and look at the others. Some tools have library implementations of common functions, and so that code can come right over. Custom nodes, on the other hand, have to be hand-written. While C is a common language for this, it’s common to use intrinsics within C to craft vision code.
But there is an OpenCL standard for coding such functions, and a subset of that is a C variant called OpenCL C. This is again a platform-independent way of coding the node. It’s what Synopsys supports; more on how that works shortly.
So you’ve got this high-level graph representing the entire application. The graph is independent of the actual processing platform, which allows you to design and test out an algorithm first and then figure out which platform is best at implementing the algorithm. We’ve seen both Cadence and Synopsys platforms here, but there could be many more. And they’re typically heterogeneous, potentially having some combination of multiple CPUs, GPUs, DSPs, and CNNs – just to name a few. Implementing the application graph means mapping the nodes in the graph – each of which is a task – to different cores in the platform and then compiling each task for its node.
So that’s how non-CNN nodes are handled. Meanwhile, for the nodes that require a CNN, training is needed to configure the CNN. As we’ve seen, that’s done through any number of training facilities – the most well-known of which would be Caffe, originating out of UC Berkeley, and TensorFlow from Google.
This training requires lots of computing, and so it happens in the cloud. What results is a graph representing the CNN, with appropriate weights or coefficients calculated through the training process. This graph is completely distinct from the higher-level app graph. Ultimately, the tool flow results in a static program representing this CNN for execution within the CNN engine.
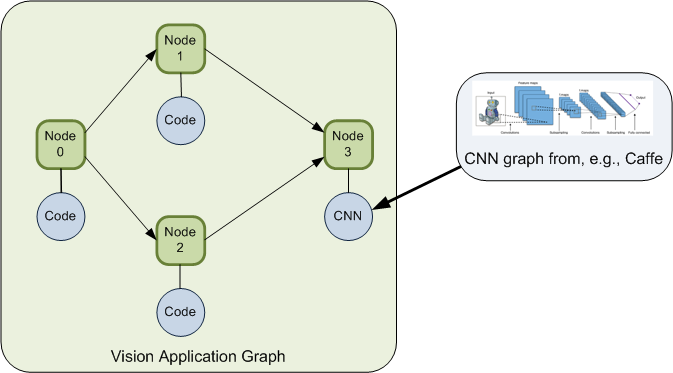
Because Synopsys has both the generic processing and the CNN engine in one block, it can implement not just a CNN graph, but an entire application graph – assuming there are sufficient computing resources. Synopsys’s tool flow supports this with what appears to be a unique ability to take the full app graph, along with its associated code bits and CNNs, and optimize the mapping onto the EV6x platform.
As a coder, you have some ability to direct how the mapping happens, but, for the most part, it’s intended to be an automatic implementation of the app graph, optimized for performance, and including DMAs, synchronization, memory mapping, and similar supporting characters so that it all works when brought together.
A given core may have multiple nodes mapped to it. In that case, the system will dynamically load the code for the appropriate task when the time comes for it to run.
The overall graph represents potential task parallelism (like Nodes 1 and 2 above); within a node, the tools also auto-parallelize the data for use by the vector processor. So at the top level, you have functional parallelism; further down, you have data parallelism. (Which echoes the vector VLIW implementation we saw with Cadence, although the one we discussed there was part of the CNN engine.)
So we’ve seen the migration from generic processors with convolutional accelerators to generic processors attached to a full CNN engine to generic processors integrated with a CNN engine in a single block. This should give you vision application designers lots to play with as you figure out the best ways to process images and video.
More info:


The Recognition Error figure shows two images of leopards.
Is ‘correct recognition’ meant to determine that both are leopards?
Or is it meant to distinguish the faces of two different leopards (different spot patterns)?
The former is relatively simple, the latter is more like what security facial recognition of humans is trying to do.
How well an image processing system performs more difficult tasks is a better measure of the capability of the system.
Or is this just a ‘hypothetical performance’ graph, not based on any objective testing.
(We engineers care about answers to the difficult questions.)
Let me see if I can get some comment from Synopsys on that.
OK, I got some comment back from Synopsys regarding the recognition data:
“In the specific example shown in the article using the AlexNet graph, the interpretation
of ‘correct recognition’ means that the CNN has determined that both are leopards.
More generally, CNN graphs can also be used to distinguish to distinguish specific
instances of an animal, face or any specific object. CNNs are definitely being used
in security applications for face recognition.
The recognition error shown in the chart is an objective measure used
to compare various CNN or classical image processing algorithms.”