


It’s a well-worn path that’s followed when new technology comes around.
It often starts in universities or large companies with big research budgets and an appetite for taking chances. There the new thing can be sussed out by patient students or engineers not graded on productivity and not facing a tape-out or go-to-market deadline. While they’re willing to struggle along, knowing that they might be on the cusp of something great, at some point, the tedious aspects of making the new technology work become… well… tedious. And so they cobble together rough-and-ready tools that will save them some work.
At a yet later point, if the New Thing shows promise, then the world becomes aware of the work and starts to chomp at the bit. When will this be ready for prime time? The results of the research efforts are made available to the public, typically involving open-source code and tools.
Those tools stand alone, and commercial designers find ways to incorporate them into a design flow. That flow may require integration with other tools; since such integration isn’t fully available at this early stage, each designer or company rolls their own.
At first, everyone is happy to have access to the cool New Thing. But, as the novelty wears off, they realize that they’re all spending time futzing with the tools. That futzing is being repeated around the world with each individual company or designer. And they realize that this is inefficient – additional structure and infrastructure would help designers to focus on the design, not the wherewithal for getting the design done.
And the designers also realize that many, many design teams are working on the same thing. Yes, part of that is about teams competing to provide the best embodiment of the new technology – one that will rocket them past the others in sales. But other parts of the design amount, more or less, to brushing their teeth: it’s something that has to be done, but they’re not going to get credit for it. And who gets excited about brushing their teeth?? (OK, besides the poor schlubs waking up with a screeching hangover and a defective memory of the past 12 hours…)
And so they start posting and looking for open-source tooth-brushing IP that they can leverage, saving them tons of effort. Which quickly renders the new, exclusive technology not quite so new or exclusive. Especially if there’s yet another new technology kid in town.
Learning Deeply
This is the call that the Linux Foundation said that they heard from their membership. Deep learning has the technology world all atwitter about what can now be done that used to be impossible (or at least really hard) to do. It’s an enormous bandwagon, and, as it rolls down the road, locals scramble to clamber aboard (probably more of them than truly fit or belong there). Honestly, it’s hard to think of a business that might not find some application (real or perceived) for machine learning.
Yeah, I said “machine learning” rather than specifically “deep learning.” I’ve been surprised that folks often put deep learning in a completely different category alongside machine learning. In fact, machine learning is a generic term that should describe anything that lets machines learn – most of which today would involve some kind of neural network.
Neural networks with more than one hidden layer are called “deep,” so deep learning is really a subset of all neural nets, which are themselves a subset of machine learning. (Which is a subset of artificial intelligence.)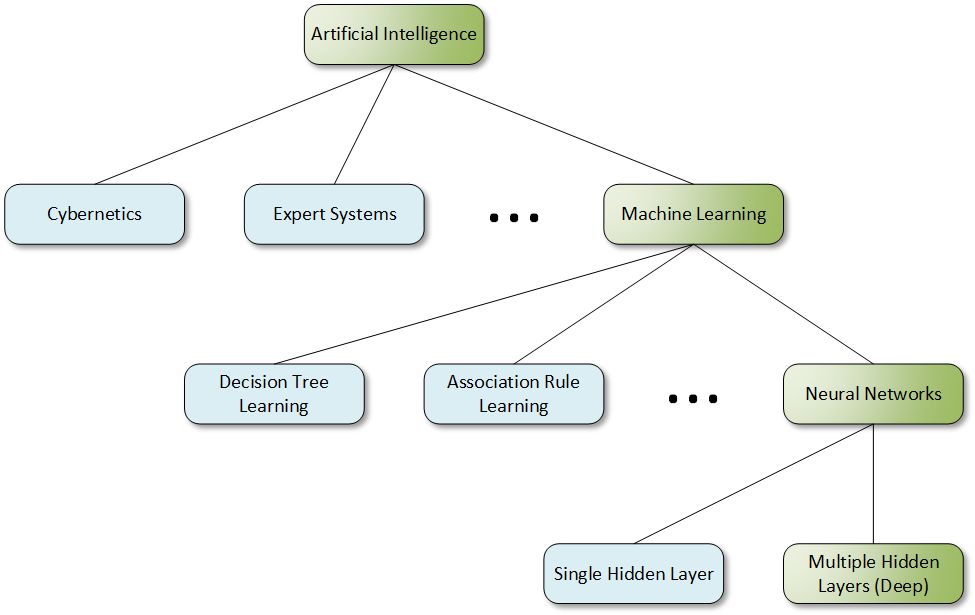
Notwithstanding this ambiguity, the Linux Foundation has established an umbrella organization that they’re calling the LF Deep Learning Foundation. This group will host a variety of projects relating to artificial intelligence (AI) and, specifically, to deep learning.
Is this about only the narrower meaning of deep learning? Realistically, many of the neural nets being readied for commercial application are deep, so the activities suggested by the name probably cover a lot of what’s happening now – and what’s likely to happen going forward. After all, how many commercial neural nets are likely to be shallow?
I checked in with the Linux Foundation to be sure of what their intentions are. They confirmed that they’re using the phrase “deep learning” in the general sense, not the literal sense. They’ll cover any kind of artificial intelligence, which includes machine learning, which includes neural nets, which includes deep learning. Kind of a tail-wagging-dog thing.
What it Is and Isn’t
The projects to be initiated under the group will need approval. There will be both a governing board, for figuring out budgets and such, and a Technical Advisory Council for helping to ensure that the different projects don’t end up acting as silos and duplicating efforts.
As they launched the foundation, they also announced the first approved project, called Acumos. This effort will establish the infrastructure necessary to create and share AI models more easily than is possible today. Yeah, it’s the last stage of that technology evolution path. Except that it’s just getting started, so there’s lots to do.
They’re tying model-creation tools like Caffe and TensorFlow together with APIs that will provide for easier integration. There will be infrastructure for developing, testing, and sharing models. Much of this is still a work in progress.
Here are a couple of things that this is not:
- It’s not an organization that will create models. Members will handle that. The Foundation will provide only the platform.
- It’s also not simply about Linux. In fact, there’s no real tie to the Linux operating system (OS) other than the organization running it. They are trying to fill a need that their membership happens to have, even if it’s not directly related to the OS.
They weren’t sure if they were the only ones doing this; I looked around a little and didn’t see anything else like it. You’ll find lots of search returns for AI development platforms, but those seem to be for the more specific neural-net tools like TensorFlow. The Acumos effort layers atop that; it doesn’t compete with it. So they may well be alone in this space, at least for the moment.
In order to be shared, models will need to use an open-source approach, including some sort of open-source license. While some such licenses are friendlier to commercial ventures that others, it reinforces the fact that much of what goes up here might end up being for brushing teeth. As with much open-source-ware, it gets tricky if you don’t want to turn open-source code into family jewels. Make-or-break models are likely to remain safely proprietary.
So if you’ve been looking for a way to stop reinventing the basic models that everyone else is reinventing, or if, perhaps, you want to take a model that’s prêt à porter and do some more training to elevate it, this may be something worth checking out.
More info:



What do you think of the LF Deep Learning Foundation in general, and the Acumos project in particular?