

One of the things I really enjoy is bacon sandwiches, but that’s not what I wanted to talk about here. Another thing I enjoy is watching a startup company evolve from being a twinkle in its founder’s eye to purveying its first product.
Way back in the mists of time we used to call May 2020 (which is two long years ago as I pen these words), Jim Turley wrote a column on the topic of Creating the Universal Processor here on EE Journal. The focus of this column was a new type of processor called Prodigy that was under development by a startup called Tachyum.
As Jim said at that time with respect to the folks at Tachyum: “Their goals are nothing if not audacious. Prodigy will be faster than Intel’s Xeon but consume one-tenth the power. It will have 4× lower cost of ownership (TCO) than current server processors. It will occupy less silicon than an ARM design. It will perform both AI and hyperscale server workloads with equal aplomb. A single version of the chip will scale between 16 and 128 cores, all in the same 6400-ball package. And it will be cheaper than Intel or AMD chips by a factor of three. That last one shouldn’t be hard to achieve. The others? We’ll have to wait and see.”
Just one year after Jim’s column — and one year before the piece you are currently perusing — I penned my own column posing the question: Are We Ready for Human Brain-Scale AI? I was just refreshing my memory regarding that column. I have it open on one of my screens as we speak. (When I say “speak,” I’m speaking metaphorically, metaphorically speaking, the saying of which reminds me of the old programmer’s saying: “In order to understand recursion, one must first understand recursion.”) In that column I may have mentioned Johnny and the Bomb by the late, great, Terry Pratchett (but “I think I got away with it,” as Basil Fawlty famously said).
The reason for my broaching this bodacious book is that it contains a character called Mrs. Tachyon — an old lady who pushes a supermarket trolley around while muttering unexpected utterances and uttering enigmatic mutterings that no one understands. It’s not going too far to say that Mrs. Tachyon puts the “eff” in “ineffable.” We eventually discover that her trolley acts as a time machine, which explains a lot of things that were puzzling us in the tale, but let’s try not to wander off into the weeds. Suffice it to say that whenever I hear news of Tachyum, it causes Mrs. Tachyon to pop into (what I laughingly call) my mind — just be grateful you aren’t in here with me (cue maniacal laughter).
The reason for my waffling here is that the wait is almost over and Tachyum has formally launched Prodigy, which is described as “the world’s first universal processor.” The underlying idea is that people are currently using different types of processors to perform different types of tasks — central processing units (CPUs) for general-purpose processing, graphics processing units (GPUs) for graphics and hardware acceleration of algorithms that process large blocks of data in parallel, and AI accelerators for artificial intelligence (AI) applications.
A really (REALLY) simplified way of visualizing this is that CPUs do their best work on scalar values, GPUs do their best work on vector values, and AI accelerators do their best work on matrix values. What Prodigy does is to unify the functionality of a CPU, GPU, and TPU into a single architecture that’s implemented on a single monolithic device.
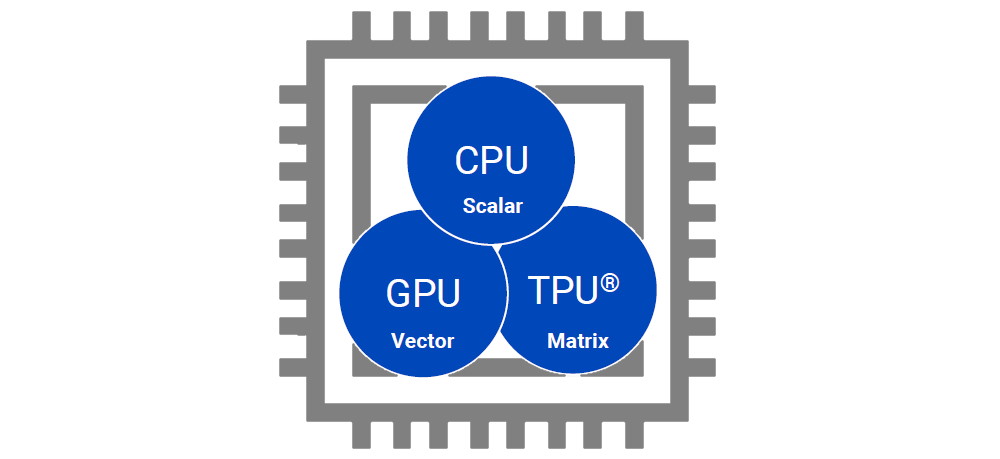
Tachyum’s Prodigy is the world’s first universal processor
(Image source: Tachyum)
This is probably a good time to note that, in the context of compute, the TLA (three-letter abbreviation) TPU is typically assumed to represent “Tensor Processing Unit.” This is an AI accelerator application-specific integrated circuit (ASIC) developed by Google specifically for neural network machine learning, particularly using Google’s own TensorFlow software. Google began using TPUs internally in 2015, making them available for third-party use in 2018. In the context of this column, however, we understand TPU to stand for “Tachyum Processing Unit.”
Implemented in an advanced 5nm process technology, Tachyum’s first commercial product — the Prodigy Cloud/AI/HPC supercomputer processor chip — offers 4x the performance of the fastest Xeon, has 3x more raw performance than NVIDIA’s H100 on HPC, and has 6x more raw performance on AI training and inference workloads, with up to 10x performance at the same power.

FPGA-based Prodigy prototype (Image source: Tachyum)
The folks at Tachyum say that Prodigy is poised to overcome the challenges of increasing data center power consumption, low server utilization, and stalled performance scaling. Some of the highlights of the newly launched Prodigy processor are as follows:
- 128 high-performance unified 64-bit cores running up to 5.7 GHz
- 16 DDR5 memory controllers
- 64 PCIe 5.0 lanes
- Multiprocessor support for 4-socket and 2-socket platforms
- Rack solutions for both air-cooled and liquid-cooled data centers
- SPECrate 2017 Integer performance of around 4x Intel 8380 and around 3x AMD 7763HPC
- Double-Precision Floating-Point performance is 3x NVIDIA H100
- AI FP8 performance is 6x NVIDIA H100
Unlike other CPU and GPU solutions, Prodigy has been designed to handle vector and matrix processing from the ground up, rather than as an afterthought. Among Prodigy’s vector and matrix features are support for a range of data types (FP64, FP32, TF32, BF16, Int8, FP8, and TAI); 2×1024-bit vector units per core; AI sparsity and super-sparsity support; and no penalty for misaligned vector loads or stores when crossing cache lines. This built-in support offers high performance for AI training and inference workloads, increases performance, and reduces memory utilization.
As the guys and gals at Tachyum delight in telling anyone who will listen, “Prodigy is significantly better than the best-performing processors currently available in hyperscale, HPC and AI markets. Prodigy delivers up to 3x the performance of the highest-performing x86 processors for cloud workloads, up to 3x compared to the highest-performing GPUs for HPC, and up to 6x for AI applications. By increasing performance while using less power, Prodigy solves the problem of sustainable data center growth by offering unparalleled carbon footprint reduction. This is especially important as the universality of AI continues to gain traction: Prodigy will enable unprecedented data center TCO savings as part of this new-world market.”
To back all of this up, the chaps and chapesses at Tachyum spent a lot of time presenting me with a mind-boggling array of charts and graphics, including the following:
- Prodigy vs. x86 (AMD 7763 & Intel 8380): FP64 Floating-Point Raw Performance.
- Prodigy vs. Nvidia H100 GPU (H100 DP & H100 AI): HPC and AI
- Prodigy vs. AMD MI250X GPU (MI250X DP & MI250 AI): HPC and AI
- Prodigy vs. x86: SPECrate 2017 Integer (AMD 7763 Performance & Intel 8380 Performance)
- Prodigy vs. Nvidia H100: Rack-Level Comparison (H100 DGX POD vs Prodigy Air cooled rack and liquid cooled)
I’m not as stupid as I look (but, there again, who could be). Using my prodigious wetware processor (which is one of my three favorite organs), I detected the subtle pattern that threaded its way through all of the bar charts, namely that all of the columns representing Tachyum’s Prodigy stand proud in the crowd compared to competitive offerings.
Sampling for Prodigy will begin later this year with volume production taking place in the 1H 2023. I don’t know about you, but I cannot wait to meet and greet my first Prodigy chip in the flesh, as it were. How about you? Do you have any thoughts you’d care to share?


Hi Max, fun to read as always. Two questions:
1) 64000 ball-grid array. Are the balls arranged as a multi-dimensional sparse matrix? Will you lay out my circuit board for me?
2) What about compilers, simulators, IDEs, design tools, and the like?
3) And the bonus EE-degree question: Do they have precise exceptions?
– Kim Rubin
(retired nemesis of retired Jim Turley)
Hi retired nemesis of retired Jim Turley — I think it’s 6,400 not 64,000 — but I agree that they have a lot of balls to present us with this package
With regard to compilers, simulators, IDEs, etc — they have a complete ecosystem. I should have written more about that. If you want to know more, email me at max@clivemaxfield.com (remind me what this is about) and I’ll share some more info with you.
Re having precise exceptions — I’ll ask them to respond to this question here — watch this space
In regards to question number 3 —–
“3) And the bonus EE-degree question: Do they have precise exceptions?”
Yes we have fully precise exceptions.
1. Hi Max, fun to read as always. Two questions:
1) 64000 ball-grid array. Are the balls arranged as a multi-dimensional sparse matrix? Will you lay out my circuit board for me? >>>> It’s 6400
>>>> Its dense 2D matrix and yes Tachyum will provide reference design to its customers including PCB layout of our 4 sockets reference design.
2) What about compilers, simulators, IDEs, design tools, and the like?
>>>> They are already available for our early adopters and demo of them is in videos on our website.
3) And the bonus EE-degree question: Do they have precise exceptions?
>>>> Yes Prodigy has precise exception model.
But can it run Crysis?
What Type of FPGA is used? Xilinx?
You have some special trick to outperform ASIC by FPGA?
6xTimes FP8 to Nvidia H100 you have emulated nvidia tensor cores? How you can compare that please publish some output from model inference or training some video please?
I tested google TPU before GPU was much better in performance, maybee lower power hungry, but you present both 6xhigher and power effective very strange…
Why wizards from tachyum ignore my questions?
Hi inder — my bad — I didn’t check for comments — I’ll ask the folks from Tachyum to respond — Max
sorry for the delay..
Sorry for the delay @inder
What Type of FPGA is used? Xilinx?
>>>> INTEL (former Altera) FPGA
You have some special trick to outperform ASIC by FPGA?
>>>> No special trick. FPGA does not outperform ASIC.
6xTimes FP8 to Nvidia H100 you have emulated nvidia tensor cores? How you can compare that please publish some output from model inference or training some video please?
>>>> It is based on NVIDIA numbers using Tensore Cores, FP8 and sparsity.
I tested google TPU before GPU was much better in performance, maybee lower power hungry, but you present both 6xhigher and power effective very strange…
>>>> Comments are based on info about TPU.
Hope this answers your questions!