


It’s been a long time coming, but I have to say that artificial intelligence (AI) is finally starting to make my life easier in meaningful ways. I know, right? I’m as surprised to hear myself saying this as I’m sure you are to be reading it.
As a brief aside, I just received an email from my chum Stephane Boucher, who is ruler of all he surveys at Embedded Related. Stephane wanted to remind me that time is running out to register for this year’s Embedded Online Conference (EOC) for anyone who wants to get an Early Bird Special price of $190.
The EOC this year will take place 24-28 April 2023, but the deadline to register for an Early Bird Special is this coming Friday 31 March. Registering will give you both live and on-demand access to all of this year’s presentations (I count 60) PLUS unlimited on-demand access for one full year to all sessions from previous editions of the conference.
In addition to giving a couple of talks myself, I see a lot of familiar faces and a bunch of presentations I want to attend. The reason for my waffling here is that one session immediately caught my eye because it directly addresses my point about AI starting to make my life easier. I’m talking about the presentation to be given by my old chum Sree Harsha Angara: ChatGPT for Embedded Systems—A Game Changer or Pure Hype?
But we digress… allow me to set the scene… deep in the mists of time we used to call 1973 when I was 16 years old, my dear old mother badgered me to learn how to type and how to take shorthand. This was when the thought of digital computers in every home and office wasn’t even a pipedream for most people. For example, when I started my university degree two years later in 1975, the only computer in the engineering department was analog in nature. We programmed this room-sized beast by setting coefficients using rotary switches and potentiometers and by connecting its various functions using flying leads.
It’s true there was a digital behemoth that serviced all the university’s departments, but it was housed in a separate structure. This magnificent monster literally filled the building in which it resided. We captured our code on decks of punched cards, carried them across town to the home of the computer, and hoped against hope that—some frabjous day—one of our programs would actually do something useful.
The point is that I never envisaged myself spending any significant amount of time typing, and I couldn’t think of any good reason why knowing how to take shorthand would do me any good in my future role as the leading engineer of my generation (I was thinking big even then).
I certainly never thought that I would eventually transition from actually doing engineering to writing about it. Thus, it’s ironic that I’ve spent much of the past two decades interviewing companies (wishing I could take shorthand) and writing articles (wishing I could type).
I should have listened to my mom!
The World Health Organization (WHO) declared COVID-19 as being a pandemic on 11 March, 2020. That was just three years ago (give or take a fortnight) as I pen these words. In one way this seems like only weeks ago. At the same time, what many of us now think of as “the before times” also seem to be a lifetime away. As just one example, I don’t recall using FaceTime or Zoom prior to the pandemic. By comparison, I now FaceTime my mother in the UK every day, and all my interviews are conducted by Zoom (or Teams, or… video conferencing applications of that ilk).
Having video recordings of my talks with subject matter experts (SMEs) from the various companies certainly helps. Until recently, however, I’ve still had to spend time reviewing each conversation and making notes to be used in the corresponding column. For each minute of video, this typically takes me at least two minutes of listening, stopping, re-winding, banging my head on my desk, and note-taking.
Artificial intelligence is starting to change all this. I should start by noting that there’s something called Otter.ai that allows you to automatically sync your Zoom cloud recordings and transcribe them. I’ve heard great things about this little rascal (happy face). Unfortunately, I’ve not been able to get it to work myself (sad face).
However, I recently ran across a jolly interesting article on the Fast Company website: 33 AI Tools You Can Try for Free. In addition to AI Chat and Search, there are AI Artwork Generators, AI Writing Tools, AI Content Summarizers, AI Visual Editors, AI Audio Tools, and—of particular interest to yours truly—AI Speech-to-Text Transcribers.
Recently, I had a video chat with Jerome Gigot, Sr. Director of AIoT at Ambarella, which specializes in creating AI vision processors for edge applications. Rather than painfully transcribing our chat myself, I just fed the audio recording of our call into Whisper, which is one of the free tools referenced in the aforementioned article. (Useful tip: As opposed to saving the output as a simple *.txt (text) file, you can instruct Whisper to save it as a *.vtt (transcription) file, which is much more useful and which you can subsequently open in Microsoft Word.) In the ten or so minutes it took this little scamp to perform its magic, I was free to engage in other activities, like grabbing a cup of coffee and commencing the introduction to this column. Now that Whisper has done the grunt work, I’m ready to rock and roll, so make yourself comfortable and we’ll begin.
Let’s start with Ambarella itself. Since its formation in 2004, the company has concentrated on providing solutions for different aspects of video processing with an emphasis on low power. The folks at Ambarella started in broadcast and camcorders. It was around 2010 when their A5S chip was used in the GoPro that they began to focus on the security market. In 2012 they released their S2, which was the first 4K chip targeted at security/surveillance cameras.
In 2015 they acquired a computer vision company called VisLab, at which time they started to concentrate on AI and computer vision. This is when they created the first incarnation of their CVflow homegrown computer vision processor. CVflow 1.0 was more of an R&D activity that didn’t really go to market. CVflow 2.0 powers a suite of vision processing chips—CV2, CV5, CV22, CV25, CV28—each offering different price/performance characteristics. These are the chips that Ambarella’s customers currently design into their security camera systems.
Now, this is where things really start to get interesting because Ambarella acquired an AI radar software company called Oculii in 2021. At the same time, they were working on the third generation of their vision processing architecture in the form of CVflow 3.0.
The current state of play is two devices, both featuring the CVflow 3.0 architecture implemented in Samsung’s 5nm process node. The first of these chips, the CV3-AD, which they announced during CES at the beginning of this year is a very high-end device with extremely high AI performance that’s targeted at L2+ to L4 levels of automation in the automotive market.
The second chip, the new CV72S SoC, is being unveiled at ISC West, which is in progress as this column goes live. Talk about “Hot off the press!” The CV72S presents Ambarella’s state-of-the-art technology at a size and cost point that fits the IoT market in general and the security/surveillance market in particular.
But what about the Oculii acquisition I mentioned earlier? Where does this fit into the picture (no pun intended)? Well, as I said, the folks at Oculii do AI radar software. They don’t build the sensors. They just do the software. More specifically, they do software that controls the radar head (sensor) in a very smart way using AI. If you take an existing radar head from a company like Infineon, NXP, or TI, then the folks at Oculii are able to increase its resolution, range, and accuracy, all while using fewer antennas with lower power consumption. (See also my column Basking in the Safety of an Automotive Radar Cocoon regarding NXP’s 28nm SAF85xx one-chip multi-core radar processor solution.)
All of this allows the CV72S to hit all of today’s hot buttons with respect to the wants and needs of the people designing today’s latest and greatest security/surveillance systems: more AI, better image quality (including color night vision), fisheye and multi-imagers (the CV72S can de-warp fisheye images in hardware), and sensor fusion between the optical and radar worlds.

Security camera market trends (Source: Ambarella)
In the case of the AI component, we aren’t talking just more AI but also better AI. The developers of today’s security/surveillance systems always want to run the newest, greatest neural networks, which invariably tend to be bigger and require more performance. The developers also want to be able to detect and identify things further away, which means they need higher resolution on their neural network, and this also requires more performance.
The “Ooh, Shiny!” thing developers are looking at now are transformer networks. These have become famous on the natural language processing (NLP) side of things with applications like ChatGPT. More recently, AI gurus realized that those same networks can be applied to video. This has led to a new class of network called vision transformers that perform better than traditional convolutional neural networks (CNNs). Unfortunately, vision transformers require dedicated hardware (sad face). Fortunately, this new hardware is found in the CV72S (happy face).
Having said this, vision transformers are only as good as the data they work with, which leads us nicely to the sensor fusion example on the right of the image above. As you can see, it’s a tad difficult to work out what we’re working with, so let me elucidate, explicate, and expound. What we are looking at here is some kind of commercial building and a parking lot. The bottom half of this image is what the camera sees at night using only its RGB visual sensor. All we can see is a white car. We could have the best transformer networks in the world, but that’s all we are ever going to see—a white car.
The top part of this image shows a point cloud generated by the radar in the camera. If we look at this radar data, we see three purple blobs towards the top along with a light blue blob. These four blobs are people. If we were watching a live video stream we could see them moving—arms swinging and legs walking—where the color coding reflects the direction of travel (the purple people are moving left while the blue person is heading right).
Performing sensor fusion between the visual and radar imagery provides a higher grade of useful information that can be extremely important for things like building protection and perimeter security, especially when environmental conditions like fog, snow, and smoke degrade the visual position of the image.
Just in case you were worried I wouldn’t present one, here’s a block diagram upon which you may feel free to feast your orbs:
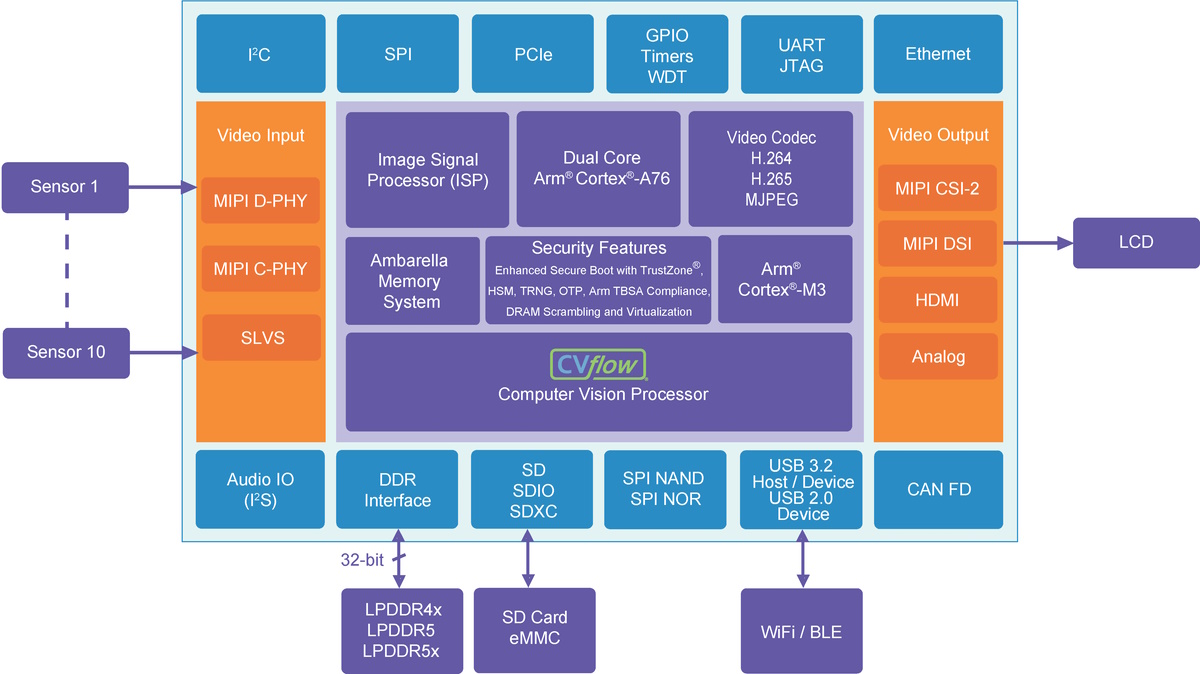
CV72S block diagram (Source: Ambarella)
I’m not going to go through this diagram in detail, save only to point out that this bodacious beauty accepts from 1 to 10 sensor (camera) inputs, it can use the latest LPDDR5 external memory, and the secret squirrel sauce is concentrated (which makes it all the tastier) in the CVflow block, whose contents your humble narrator is forbidden to even speculate on, although I will take a WAG (wild-ass guess) that it involves an eye-watering number of transistors.
My wife (Gina the Gorgeous) and I have security cameras mounted in the eves of our home. The images they provide are groovy in the day, but they are grotty at night, which—when you come to think about it—is when you really want them to be the best that they can be.
If you look at the image on the left below, this is passing through a traditional ISP engine, which is already best-in-class in this market. At some point, when the light level falls too low, the sensor becomes very, very noisy. There’s not much you can do with traditional techniques to recover this image, so typically what cameras will do when dusk falls is switch to night mode, which results in grotty gray-scale images.

AI-enhanced signal processing (Source: Ambarella)
This is where AISP comes into the picture (again, no pun intended), where the AISP moniker reflects the combination of the best traditional image signal processing (ISP) and high-performance neural network AI processing to reduce noise and improve night-time image quality while also dramatically cutting the bitrate as illustrated by the image on the right.
What? You are tired of reading my ramblings and you want to see a video? Well, by some strange quirk of fate, I just happen to have this video standing by in case of an emergency.
Last, but certainly not least, we need to consider how developers incorporate the CV72S into their security/surveillance camera designs. The way this works is that these little scamps will already have their AI network trained in 32-bit floating-point on a GPU farm. Such a network is not optimized for use on an edge device, so the guys and gals at Ambarella provide what is essentially a compiler that takes the 32-bit floating-point representation and quantizes it into an 8-bit fixed-point equivalent in a language the CV72S understands. If the developers want to optimize the model further, they can use Ambarella’s tools to prune the network. Sometimes it’s possible to prune up to 50% resulting in a linear 2X performance acceleration while maintaining 99% accuracy, which is very cool indeed.
I can’t help myself. I love a colorful picture, so it’s jolly lucky that I have one available to me as shown below.

Looking at the world through the eyes of the CV72S (Source: Ambarella)
As usual, I’ve only managed to provide a high-level overview of this technology. Hopefully, however, I’ve covered enough that you are keen to learn more, in which case the chaps and chapesses at Ambarella would be delighted to hear from you (please make free to tell them, “Max says Hi!”). In the meantime, as always, I welcome your insightful comments, perspicacious questions, and sagacious suggestions.


One thought on “Next-Gen AI Vision Processors Target Edge Applications”