


“Too many cooks spoil the broth” — proverb
Programming with parallelism is sometimes illustrated with a kitchen example. One cook working by himself has to do everything in sequence: turn on the stove, mix the batter, pour the sauce, grill the meat, etc. That’s serial programming with no parallelism. That’s how all computers worked until fairly recently.
But two cooks can work faster than one. While one stirs the batter, the other can be checking on the meat or seasoning the broth. Ideally, the work gets done twice as fast. In practice, it’s not usually that perfectly efficient, but, even so, two heads are almost always better than one.
Taken to extremes, you might think that 20 cooks in the kitchen would work 20 times faster. A soufflé in 15 seconds! A medium steak in under a minute! But of course, that’s not how it really works. That many cooks will get in each other’s way, colliding and bumping and interfering with everything. Not to mention arguing over who gets to use the whisk. There’s such a thing as too much togetherness.
The same rule applies to programming parallelism. A little is good; more isn’t always better. That’s why the processor in your laptop probably has four or eight CPU cores, not 128 of them. As the number of CPU cores goes up, so does the likelihood of interference. Get too many CPUs in a cramped space, and it’s all elbows and arguments.
Stretching our kitchen analogy just a bit further, the tougher problem is finding recipes that can exploit parallelism. If you’re baking a cake while also grilling a steak, it’s pretty easy to allocate those two tasks to different cooks. But if you’re both trying to stuff the same turkey or boil the same pot of pasta, it’s not clear how you’d split up that work. Some recipes, like some computer programs, simply don’t lend themselves to parallel execution. There’s not much you can do to accelerate the work if the work itself defies parallelism.
Fortunately for us, there are some common computer algorithms that can be parallelized. Database searches, mapping, rendering, simulations, and some forms of cryptography can be readily parallelized, and therefore accelerated if you have the right hardware. Again, that’s why your laptop’s processor probably has four or eight CPU cores instead of just one.
For the most part, the world’s microprocessor companies have found that 16 CPU cores is about the limit of practical acceleration. More than that, and the cooks just get in each other’s way again. The overhead involved in orchestrating that many CPU cores – not to mention the complexity of the programming model – makes n-way parallelism prohibitive for large values of n.
But…
Researchers at MIT have developed a new type of microprocessor that seems, at first blush, to vastly increase the performance of parallel programs. And by faster, they mean 50 times to 100 times faster. As in, two orders of magnitude faster. A lot faster.
They call it Swarm, and the initial simulation results look pretty spectacular. On the other hand, Swarm is only in the simulation stage; it’s never been built in hardware, not even as an FPGA prototype. And Swarm is designed mostly for a narrow class of highly parallel programs where its unique design can shine. It’s probably not very good at running Windows, Linux, or your favorite word processor.
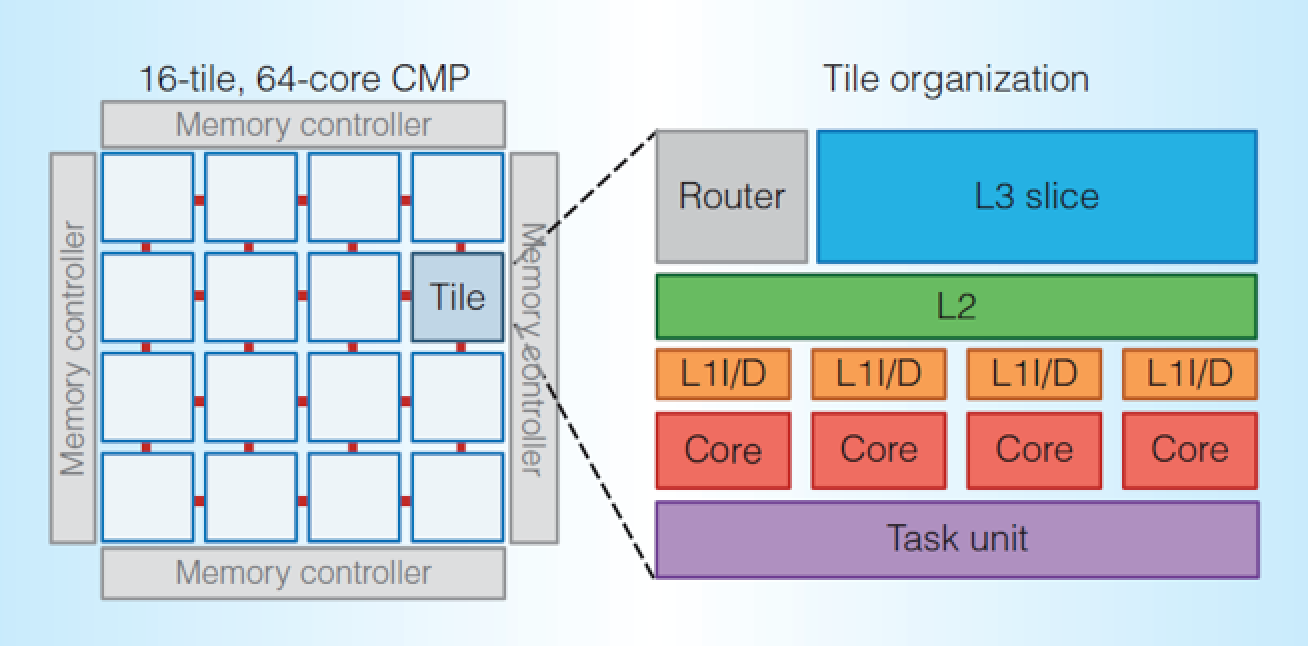
Swarm combines the familiar with the unusual. At first glance, it’s just a cluster of 64 identical CPU cores on a single chip, connected via a network of on-chip buses. There are caches, memory interfaces, clock buffers, and all the usual accoutrements of a typical multicore microprocessor.
The chip is divided into 16 equal “tiles” in a symmetrical 4×4 array. Each tile includes four identical CPU cores. Each CPU core has its own L1 cache; the L2 cache is shared among the four CPUs within the tile; and there’s one huge global L3 cache that is shared among all 16 tiles (64 CPU cores) on the chip, although it’s physically implemented in 16 slices, with one piece of the cache inside each tile.
But underneath all that is Swarm’s secret sauce. It includes a remarkably complex hardware system for inter-process communication and synchronization. And it’s this synchronization hardware, not the CPUs themselves, that make Swarm so fast.
Swarm’s creators at MIT realized what so many other parallel-computing researchers have found: that the bottleneck to fast parallel processing isn’t the processing itself; it’s the coordination among tasks. Doing the work is easy; figuring out how to do the work is hard. This is one case where a good supervisor is more important than the workers he oversees.
To that end, Swarm divides software tasks into very small subroutines. These might be only a few dozen instructions each, up to a few thousand instructions, but no more. Each tiny task is then randomly assigned to one of Swarm’s 64 CPU cores. Thus, Swarm can potentially handle up to 64 tiny tasks simultaneously.
Very few programs (apart from artificial benchmarks) have 64 routines they can execute simultaneously. There are usually too many dependencies and interrelationships to launch new tasks until the results of previous tasks are known. In other words, you can’t add C+F until you know the results of A+B=C and D+E=F.
Right?
Swarm doesn’t care. It’s designed to keep most or all of its 64 CPU cores busy, no matter what they have to do, even if it means speculatively executing some tasks and throwing away the results. It’s all about work, work, work, and worry about the outcome later. In MIT’s simulations, this counterintuitive approach yields very good results – at least, for the types of tasks that Swarm’s creators simulated. They’ve seen speedups of 43x to 117x over conventional serialized implementations, and 3x to 18x improvements over “state of the art” parallel implementations. In other words, Swarm appears to be at least three times faster than anything else you can do today. Not bad.
Data dependencies are often the biggest bugaboo for parallel processors, but Swarm simply postpones reconciling those dependencies until very late in the game. Instead, it dispatches every tiny task it can find, on the theory that it’s better to get the work done early and then decide later whether to keep the results. Most CPUs today take the opposite approach: they resolve dependencies first and then dispatch and execute the dependent code. This avoids a lot of wasted effort but it also delays launching (and thus resolving) tasks until you’re sure they’re useful.
To allow this extraordinarily high level of speculation to work, Swarm needs a lot of CPU cores at its disposal, and it has them. It also needs an elaborate system of buffers and queues to keep track of all the speculative results. Every tiny task executing on each CPU stores its results in a buffer, along with its task ID and a timestamp. When the task completes, a new task takes its place on the same CPU core, and so on. That core’s buffer starts accumulating the results of several speculative tasks, none of which have been committed to the “official” machine state yet. There’s whole lotta buffering going on.
At regular intervals (the ideal timing of which depends on the overall algorithm the chip is executing), Swarm sends out a global signal to all of its 64 CPU cores that it’s time to commit to all the valid results and abort all the invalid ones. This is where the timestamps come into play.
Normally, an RTOS or other multitasking scheduler would maintain a linked list of tasks so that it can tell which parent tasks spawned which child tasks. That allows it to know which tasks are dependent on one another. If Task A spawns Task B, but Task A is later found to be invalid, irrelevant, or unnecessary, then you want to kill off Task B before it starts. Or, if it’s already started, you want to abort its results before they’re saved. You also want to be sure that Task B doesn’t update any shared memory values unless you’re sure it’s a valid task.
Swarm doesn’t do any of that. Instead, it time-stamps each tiny task. Tasks are dispatched in timestamp order to any random CPU that’s free at the moment. But, more importantly, the timestamps are used to determine dependencies. If an “upstream” task with an earlier timestamp is found to be invalid, everything downstream that’s related to it is aborted.
This is trickier than it sounds. With so many tasks executing at once, many of them speculatively, there’s a lot of work going on that might have to be undone. For example, you don’t want a task writing to shared memory unless you’re certain it’s a valid task and not destined to be aborted. But if you wait until you know its status, you’ve lost time. How to reconcile system stability versus time management?
You do it with lots and lots of really big buffers, combined with some elaborate cache management and lookup tables. Swarm’s hardware uses write buffers extensively. Memory writes are not committed until (and unless) the task writing them has been deemed valid. Until then, it’s just queued. Because many different tasks might be trying to write to the same memory location, Swarm must maintain a cache-like buffer of all of these pending writes, arranged in timestamp order. But it also has to service read requests from other tasks accessing the same location, also possibly speculatively. To speed things up a bit, Swarm uses a so-called Bloom filter to quickly decide whether the target address is lurking somewhere in this buffer, and, if so, to return the results from the buffer, not from memory.
Confused yet? We’re just getting started. For every write access that hits the cache, Swarm also stores the old, “stale” data, just in case the update is aborted and the original value has to be restored. With up to 64 CPU cores all running various tiny tasks, Swarm rapidly accumulates speculative results from all of them. The periodic sync then commits all the valid results, flushes the rest, and the process starts over.
Unwinding that many speculative tasks is a chore. Any task could spawn any number of child tasks, and if the parent task is deemed invalid, all of its children have to be located and cancelled and their results undone. Swarm recursively walks each task’s write queue, restoring the old values. If the aborted task touches any memory locations used by other, unrelated, tasks, then Swarm has to abort them as well. Swarm also must clear the tags and flush the cache lines for anything the aborted task has touched, lest it contaminate a downstream task with incorrect data.
In Swarm, commits are fast; aborts are slow and laborious. But that’s what you want when you’re seeking performance: you optimize for the best case. The performance hit for aborted tasks isn’t relevant because, hey, they were aborted anyway. On the other hand, those aborted tasks did take up space (in the sense of consuming execution resources) and they burned energy, so they do come with a cost.
You might say that Swarm throws spaghetti at the wall to see what sticks. It executes everything it possibly can, knowing full well that some portion of the results will be discarded, their effort completely wasted. That proportion depends entirely on the algorithm it’s executing and how well it maps onto 64 identical processor cores. Swarm hopes for the best but plans for the worst.
So what is Swarm good for? Obviously, it’s intended for highly parallelizable tasks, and there are plenty of real-world examples of those, as well as some abstract mathematical specimens.
One algorithm that the MIT team simulated was Dijkstra’s single-source, shortest-path (sssp) algorithm, which is basically an abstract version of Google Maps, Waze, or similar pathfinding apps. Their seemingly magical ability to find the shortest route between two points on a roadmap is really just a brute-force analysis of every available path, beginning at the starting point and exhaustively testing every intersection along the way. They’re dumb but they’re fast. Fast enough to be useful to us humans, anyway.
They’re also good examples of parallelizable tasks. If you’re going to evaluate n possible routes between Point A and Point B, where n is somewhere in the thousands, you’re going to want to run those checks in parallel. It’s also convenient that each route is independent of all the others. That is, you can evaluate Route 1 at the same time as Route 2 because their outcomes have no bearing on each other. You’re simply evaluating a few thousand different routes, not adding them all together.
The trouble with this brute-force approach is that the number of paths in any real-world roadmap is very nearly infinite. If you’re planning a drive from San Francisco to Boston, there are a lot of roads through the continental United States (and Canada, Mexico, Guatemala, Panama, et al.) that you could potentially cover and still reach your destination. Yes, they’d all be ridiculous detours, but the computer doesn’t know that.
What Dijkstra’s algorithm does is to greatly reduce the amount of wasted effort by eliminating dead-end paths or absurdly long and circuitous routes. This perfectly matches Swarm’s architecture because sssp consists of a lot of very small tasks running in parallel, with only some modest sharing of data among them. It’s also a worst-case scenario for many other processors, because even a small amount of synchronization overhead (from inter-task communication, semaphores, spinlocks, etc.) could swamp the benefits of the parallelism. For something like this to work on a Dijkstra problem, the overhead must be minimal, quick, and efficient.
Because Swarm is so well suited to Dijkstra’s sssp, it saw the best speedup of all the algorithms reported – 117x the speed of a purely serial implementation and about 8x faster than a software-parallel implementation. If mapping is your business, that’s a big deal.
What if mapping isn’t your business? Is Swarm your next processor? Probably not. In fact, you could argue that Swarm isn’t even a general-purpose microprocessor at all. It’s more of a programmable accelerator. Maybe that’s just semantic hair-splitting, but it highlights Swarm’s laser focus on parallelizable tasks. It’s very good at tasks that can be broken up into very small, identical, and independent pieces. For everything else? We don’t know.
There’s no reason to believe that Swarm would be worse than a conventional processor at running conventional software. But that depends on what you’re measuring. Conventional wisdom, backed by years of experimentation, says that massive speculation is massively wasteful. Wasteful of power and wasteful of silicon area. Any time you’re executing dozens of tasks, buffering the results, checking constantly for conflicts, and then abandoning every bit of that effort, you know you’re wasting time and energy. Intel, AMD, and other high-end CPU design houses all ran into this problem a long time ago, and they intentionally scaled back their chips’ speculative execution in order to save energy. Swarm is not intended to be a low-power processor.
Compared to a conventional microprocessor – even a very high-end one with lots of computing resources and elaborate multi-level caches – Swarm is pretty weird. It allocates an unusually large proportion of its logic to timekeeping, tags, commit buffers, queues, arbiters, and other nontraditional circuits. The CPU cores themselves are almost an afterthought. Tellingly, the MIT paper never even discusses Swarm’s instruction set or what kind of execution resources it has (it’s an x86). That’s kind of like showing off a new car by demonstrating the radio while never popping the hood to look at the engine.
Still, there’s nothing wrong with unconventional approaches, per se. Today’s multicore CPUs, on-chip caches, and register reordering all seemed pretty outlandish at the time, too.
Swarm might be a completely reasonable architecture if you’re Google and you want to accelerate your mapping algorithms, but is performance on Google Maps really a problem that needs solving? Mapping apps, like word-processing programs, are already faster than their human users need them to be. Having said that, Google does have a team of in-house CPU designers. So does Facebook, and so do many other firms you wouldn’t expect. So special-purpose processors can and do find well-funded homes.
Regardless of its immediate commercial prospects, Swarm pushes out the boundaries of current knowledge about parallelism, and that’s a good thing. It emphasizes inter-task synchronization and communication over mere instruction-set architecture. That’s also a good thing. Maybe future processors will adopt some of Swarm’s ideas, wrapped around a cluster of ARM cores, or x86 cores, or nVidia cores. Who knows? Kudos to MIT for tackling the parallelism problem at its root and coming up with an unusual solution.


I wonder if human brain works this way.
Parallel processing isn’t new, despite the marketing hype. It’s been a fundamental part of computing, especially niche application computing, for nearly 50 years, with the limit’s clear set from the beginning with Amdahl’s law and Gustafson’s law.
Flynn’s taxonomy allows a designer to understand the applications processing models, trade-offs, and needs. There has been more than one unskilled parallel product architect fail to understand these basics … and deliver a system with miss-matched expectations.
The serial part of Amdahl’s law, frequently becomes the memory or storage subsystems, which high core count CPU’s are likely to block on. The other extremes are GPU designs with high memory bandwidth, yet lack flexibility because of their SIMD/MIMD SPMD architecture only supports a single thread, or limited threads with a highly specialized instruction set.
Thermal management is a critical limit, and doing lots of non-productive tasks to be discarded creates both heat and lots of wasted power … short battery life, or very poor work per watt stats.
For any dedicated task that can be done with 64 threads of “only a few dozen instructions each, up to a few thousand instructions” I’m pretty certain can be done cheaper, faster, and with SIGNIFICANTLY lower power using an FPGA with a combination of dedicated logic and multiple small soft processor cores, supporting one or more hard processor cores in the FPGA.
Before getting really excited about the possibilities of 64 cores, learn the skills needed to understand these architectures … and dig in a little with some hands on. Either take a modern parallel programming class at a nearby university as continuing education …. or seriously pick-up the text book, and really take the time to program examples of each. Most modern desktops or laptops have multiple core CPU’s, and a programmable GPU with OpenCL or CUDA support. Get a Parallella-16 board, and practice. Spend some time with OpenMP and your multiple core desktop/laptop.
And do your research about how many of these multiple core advanced architecture CPU companies fold without finding a major design win, because frequently the system level costs don’t scale for most applications. IE a very narrow niche application market.
A more general solution is frequently a broad win, like an Intel 10 Core i7-6950X cpu supporting 20 threads. Or an Intel desktop 4-core 8 thread cpu with programmable GPU like the Core i7-6785R that supports OpenCL with around 1.1 TFLOPS
It really comes down to what KIND of parallelism does your application require.