


Everyone knows that, when developing software, you are going to have to spend a lot of time testing: identifying the bugs that are causing the software to fail, correcting the bugs, and then testing again. This phase has been estimated to take as much as 70% of the software development time for an embedded product. Last week, I attended a conference on intelligent testing, expecting to hear from a range of speakers on how their tools, research, or consultancy could improve or shorten the testing cycle. And, indeed, there was some discussion of specific tools – as we will see later. But two papers were different. The most pertinent was by Jim Thomas, a consultant who has a background of test tool development.
Before we look at Jim’s arguments, we need a brief discussion on the context. There seemed to be two different elements in the audience: those working on enterprise projects and those working on embedded projects. In the enterprise environment, developers and testers are separate breeds, and developers classically “throw completed code over the wall” to have it tested in a QA department. Testers may not be able to write code but may have domain knowledge. In the embedded world, there is frequently a less clear-cut distinction, and, often, people test their own code.
Also an underlying element in much of the discussion was the V model (see Figure 1). This approach starts by defining the overall system requirements and translating these into a system design and then into an architectural design, which is de-composed into functional models. These are coded, and the modules are tested at unit testing. Once the units are running well, then integration testing looks at how the combined modules play together, and system testing looks at whether the system, hardware and software, runs. Acceptance testing is whether the system does what it should. In fig 1, a series of test design phases runs down the middle of the V. In practice, frequently, these designs are carried out only when that level of test is about to begin.
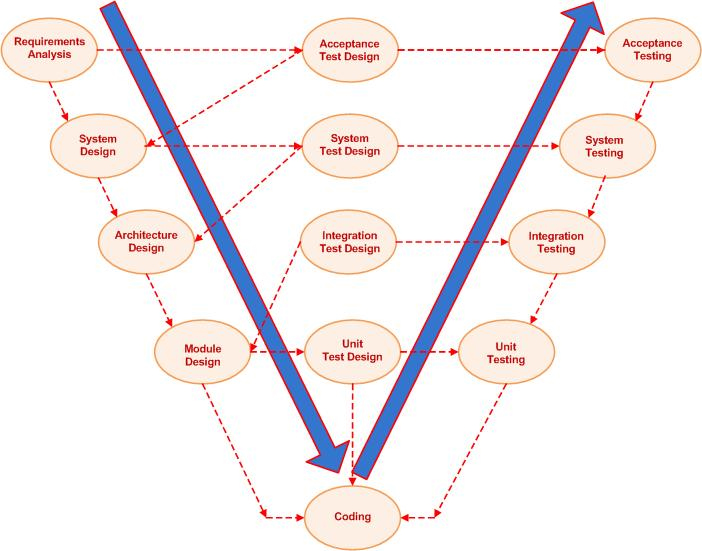
Figure 1. The V model of software development
Jim argues that the test criteria and test designs should form a part of the main design phases: shifting left. He looked at work from over the last 12 years that showed that this approach caught bugs earlier, saved time and resources, produced code that was more easily testable, sped up bug fixing, and allowed more tests to be carried out. It also seemed to create more integrated teams, with the QA function becoming a part of the team rather than a separate police force.
Finding bugs early has long been known as a massive cost saver. If the cost of fixing a defect identified at the requirements stage is given a nominal value of 1 unit, fixing it at coding time costs 10 units, and acceptance testing costs 50 units. If a bug is identified when the system is deployed, the cost of fixing it can be 150 units or more – it can even cost a company its future.
Now, nothing comes for free, and shifting left like this – taking on board this approach and incorporating inspections and reviews of designs and code carrying out static analysis of the code and involving Test/QA earlier – can front-load the project costs. But the result is shorter projects using fewer resources overall, as the upfront costs are more than offset by less time and effort spent on bug hunting during the testing phases.
While this wasn’t the keynote, in some ways it was the spine on which the rest of the presentations could be hung. The other paper that wasn’t specifically about testing was from Infineon, and it looked at the results of using a requirements management tool, Visure in this case, at the first stage of the V model. The decision to start using a requirements management tool was under consideration as part of a general move towards more structured project development, but it became inevitable after ISO 26262 was finalised in late 2011. ISO 26262 is a standard for the functional safety of automotive electronic equipment, and within it is the need for requirements specification as part of the development methodology. As Infineon targets the automotive with its AURIX Tricore product family, it is important to ensure that its development complies with the standard’s requirements.
Besides meeting the compliance demands of a standard, requirements management brings other benefits to a project. Spelling out requirements unambiguously, while not simple, has enormous benefits, and it provides a structure for the rest of the development cycle. At each stage in the design process, every decision has to be linked to a requirement and documented, and, during testing, each element’s behaviour has to meet the appropriate requirement. To ensure that the documentation is properly related requires every document to carry metadata describing its content and role, particularly if more than one format is being used. The documentation should, ideally, all be held within a single database.
If change requests are needed (and when aren’t they?), they have to be spelled out in the same detail as the initial requirements and linked to specific requirements. This makes it possible to link to the appropriate parts of the design. It is also much easier to put in place the left shift that we discussed earlier. The requirements give a clear set of targets to test against.
But these benefits carry a cost. Firstly, since engineers don’t like writing documentation, introducing requirements management may require a culture change, and that requires strong support from higher levels of management. The very first project using this approach can be time-consuming and will require determination to drive it through. But, once the system is established and accepted, it can produce projects that run more smoothly, since there should be no confusion over communication between different parts of the development team, and the end result should be a product that can be audited and where all parts of the deliverable can be shown to be meeting a specific requirement. Properly written requirements can also be reused in later projects.
So far, we have looked at two linked approaches that are designed to make testing easier, but how do we test?
Barry Lock from Lauterbach, the emulator and debugger company, looked at how it is now possible, with the ARM trace port, to see exactly how the processor core has executed the code. Downloading this information onto a PC provides the opportunity to carry out detailed analysis of how the code performed, including best and worst case timings, cache analysis, power consumption by software function, core loading, etc. This doesn’t require inserting any instrumentation into the code, so what is being examined is real code running on a real processor. Lauterbach claims that an analysis of 200 projects using trace port showed a 75% reduction in debug time. The same trace port is used on ARM multicore devices with the output showing how each core is executing code, and Lauterbach tools allow you to look at the operation of two or more cores at the same time.
It can also look at what areas of the code are not being exercised. Lock explained that ARM had been philanthropic in devoting significant areas of silicon in its cores to providing trace functionality, but it was driven by hard economic realities as it became increasingly concerned about the high failure rate of embedded projects, with an attendant loss of licence income. He also provided war stories – for example, a car dashboard supplier lost seven months because they chose a chip without trace and it took them that long to find a stubborn bug. This was topped by a telecoms project that is three years late, and anonymous companies that have gone out of business because they were unable to get the software for a product to work.
Two presentations described software tools for testing. Coveritas talked about Vitaq, the company’s product that uses constrained random generation: tests that are generated randomly, within the constraints of a rule set defined by the requirements and by the parameters of the environment in which the system will operate, such as input definitions, protocol definitions, I.O., relationships, and dependencies. This provides far better test coverage of large areas of code and was described in more detail last year in Does the World Need a New Verification Technology?
QA Systems described Cantata, the company’s unit and integration test tool. For each unit, Cantata starts from the requirements to produce test scripts and creates stubs that mimic objects that are called by the unit. The tool reports on the results of these tests and also provides analysis of code coverage: how much code has been tested and which areas are not being exercised. It provides ways to increase code coverage with table-driven tests and the option to automate tests and optimise these tests. There are also options for looking at static data and functions within the unit.
This exercises the code within the unit. But it is also important to know how the unit functions as a part of the system. Here the approach is to create a wrapper – a buffer between the source code and the called objects – that monitors the parameters of the call and if necessary modifies them and does the same for the response.
In the conference keynote presentation, test legend Dorothy Graham looked at the some of the myths and opportunities for automating testing. Her conclusions are pretty stark. Automating testing is not a silver bullet. It can be difficult and time-consuming to implement, and it is not easy to demonstrate a serious return on investment. There are areas where only a manual tester can provide the insight that makes a test worthwhile. However, properly implemented (which requires management support), automated testing can improve the quality of testing by carrying out more relevant tests and finding more bugs than can be done by hand.
So we conclude that the opening statement – that everybody knows that testing is inevitable and time-consuming – can be wrong, but to make it so by making the left shift requires an investment in getting the requirements and subsequent designs right, in considering how these will be tested at the same time as they are being developed, in choosing the right processor that gives you information about code execution, and in choosing tools that provide you with intelligent help in creating and running tests.
The presentations and slides are online at http://testandverification.com/intelligent-testing/



Do you have any thoughts on how to resolve the testing problem