


Five or so years ago, motion was getting all the MEMS and sensor love. Everything was about inertial sensors and what you could do with them to keep from getting lost.
Well, times have changed, and the flavor-of-the-month has changed with it. I noted recently the focus on audio at last fall’s MEMS Executive Congress, and, in the months since then, the industry seems to have doubled down on that focus – especially when it comes to voice recognition.
So today we bring you three new voice recognition stories, each with its unique angle.
Shhhhhhh…
We start with the real problem that would seem to complicate any kind of application relying on voice: noise. It’s not that voice recognition itself is so hard (ok, it probably is, but… relatively speaking…); it’s that the various voice engines have a hard time dealing with a raw audio signal that contains lots of background (or other) noise.
The typical approach to solving this, according to Kopin, is to try to cancel the noise. The problem, they say, is that doing so messes up the remaining voice track in non-linear ways, making the resulting stream difficult for upstream engines (like voice recognition) to deal with.
So Kopin has built what they call their “WhisperChip.” It uses a different approach, which, I must admit, sounds rather nuanced. Rather than cancelling or removing noise, they use artificial intelligence (AI) techniques to extract the voice signal. That specific distinction would likely be clearer with lots of detail on the low-level techniques involved (secret sauce), but their measurements do seem to indicate that they’re doing something well.
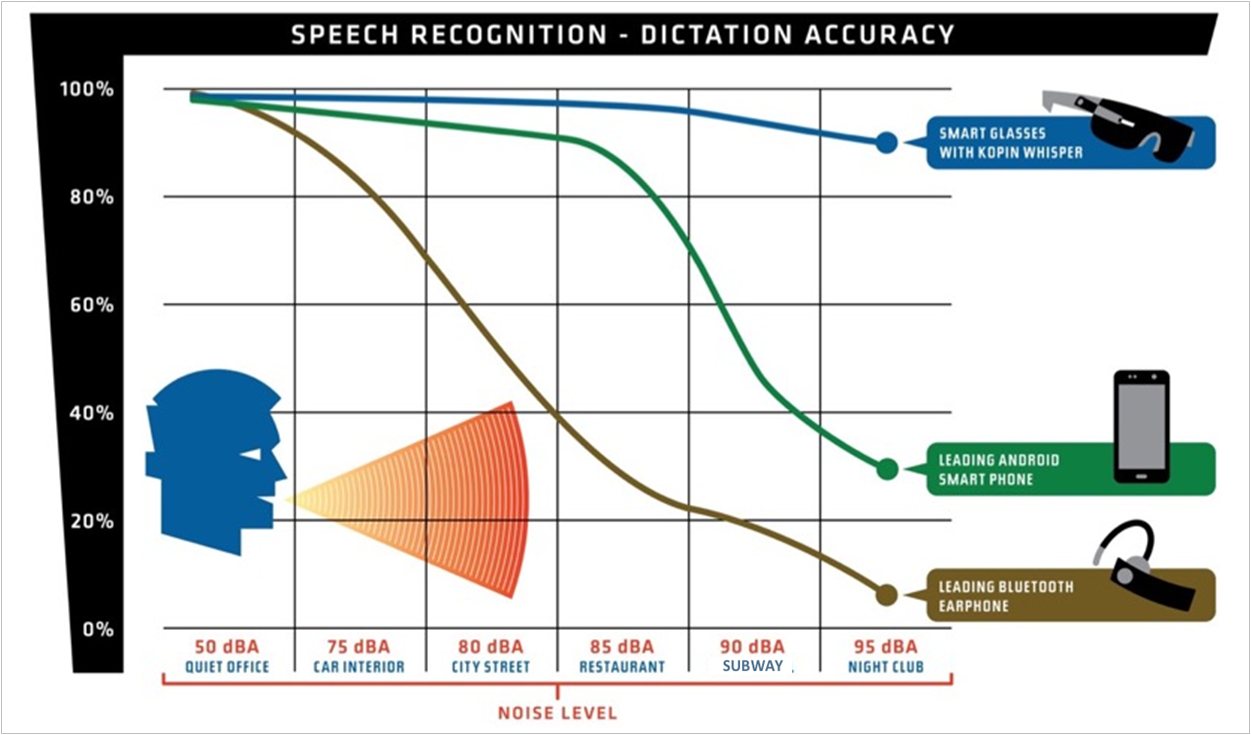
They compared dictation accuracy between their chip, a recent Android smartphone, and a Bluetooth earphone in numerous different environments with varying noise levels, from a quiet office to a nightclub. (Note that the dBA metric is a dB measurement, but with a specific frequency weighting that better reflects what the human ear perceives.)
(Image courtesy Kopin)
You can see that the earphone starts losing accuracy with the slightest injection of noise; the smartphone does OK until the main course comes at the restaurant. But the WhisperChip, as implemented in a pair of smart glasses, maintains accuracy to about 90% in the nightclub.
They’ve set this up for near-field sound (although it can be tuned or adapted for far-away sources), with wearables as an obvious first target. It takes the streams from 2-4 microphones and processes them on-chip to deliver the cleaned-up stream to the voice-recognition engine.
Their overarching goal (as indicated by the chip name) is to allow people to speak softly to their gadgetry, solving the social problem of crowds of people yelling at their devices. (Which, I guess, is its own form of noise reduction…) They say that you can literally go down to a whisper and have it still work. If that’s true, then it says something about the stream they’re extracting, since, when whispering, you’re not engaging the voicebox – eliminating that source of sound as well as all the body resonances that don’t resonate during a whisper.
A new sensor fusion
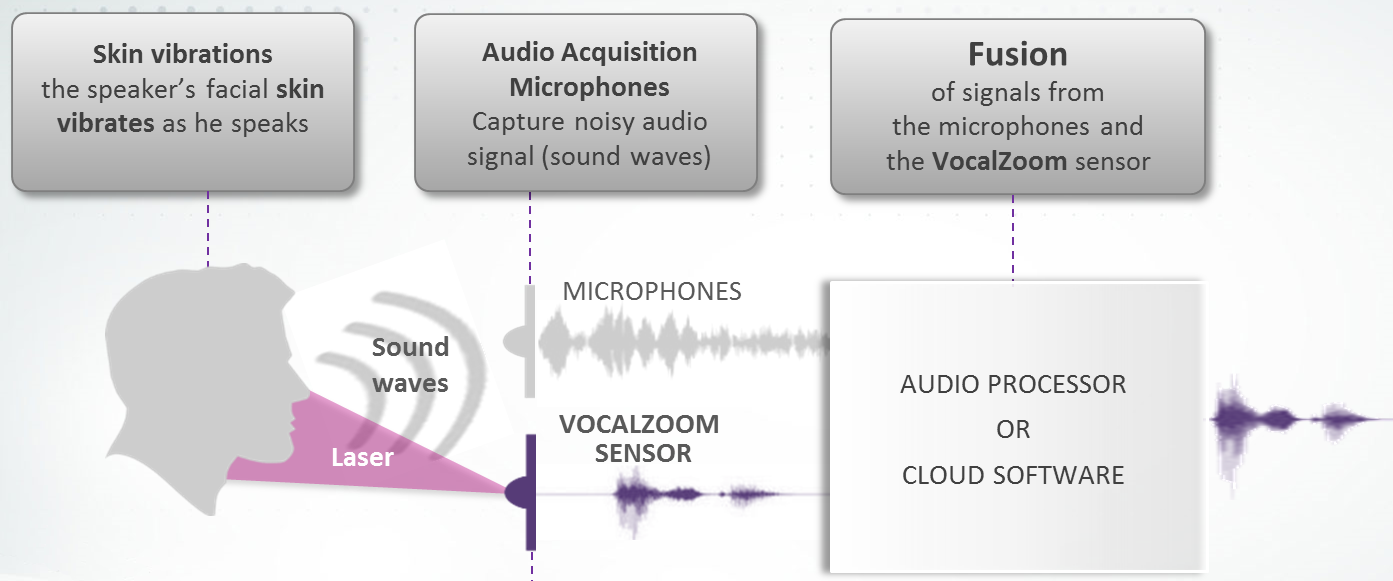
The next approach is radically different, and it comes from a company called VocalZoom. You may recall sensor fusion – a big deal with motion sensors, using gyros and mag sensors and accelerometers to provide checks and balances by combining their outputs. Well, here we have the same thing going on, except that they’re combining the audio signal with – effectively – a lidar signal.
We just talked about lidar recently, and you could argue whether, strictly speaking, this is lidar, but it’s darn close. The idea is that they’re fusing the skin vibrations that they can visually detect with the audio associated with those vibrations to exclude sound from the audio that isn’t part of the visual. In other words, if you say something and someone next to you talks at the same time, your facial vibrations will be about only what you said, not the neighbor, allowing the other voice to be rejected.
(Image courtesy VocalZoom)
You may know that some existing microphones rely on human bones to conduct vibrations; this isn’t that. In fact, Kopin finds more content in the vibrations of soft tissue – it’s just that it’s harder to measure. And this is where the lidar-like thing comes in.
They detect these vibrations by sending laser light out and measuring its return. You might expect them to aim for a specific spot on, say, your neck for best results. But let’s think about where one might use something like this. Unlike the Kopin approach, which is suited to wearables, one of the early applications for the VocalZoom technology is in a car. So imagine this, say, embedded in the rear-view mirror.
If there’s a specific point it has to aim at, then the driver has to be correctly positioned – including being the correct height – in order for this to work. That wouldn’t be such a great plan. Instead, they scan a wider field so that there is less dependency on the driver’s position. They’ve not received any interest in detecting both driver and passenger voices up to this point, but if they were to do that, they could either use a second sensor, or they could widen the scan field.
The scanning thing might sound similar to lidar on a car, but it’s different in a couple of ways. First, in the scan: they originally had a single laser and a rotating mirror, but they wanted to reduce cost and increase reliability, so they went instead for a laser array – no moving parts.
Now… the thing about a single laser and a mirror is that you can have a detector that catches the reflection, and there’s no question about which laser the light came from – since there’s only one. But if you have an array of lasers, then what? What if I said that this unit doesn’t even have a separate detector for the return signal?
In fact, in the second departure from automotive lidar, the lasers are their own detectors. And this is pretty crazy stuff, because we have to solve a couple of problems. First, we need to figure out how a laser can be its own detector, and, after that, we need to figure out how these lasers won’t be confused by all the other lasers in the array – how do they detect only their own reflection?
Here they leverage an effect called “self-mixing,” and, for this application, the laser operates continuously rather than pulsing. It turns out that, because of the coherency of the light, a continuous signal, when reflected, re-enters the laser and mixes with the internal resonating light. The effect that has on the internal behavior can be measured.
They measure both position and velocity. Of course, those aren’t independent, since velocity is the first derivative of position. But they don’t measure position and calculate the change to get velocity: they measure both independently, at the same time.
Position information comes from phase: if the target is stationary, then you’re getting the exact same light back, but with a different phase. This tells you how far away the target is. But phase is periodic; there are multiple positions that will yield the same phase change. Then again, it depends on whether you’re measuring absolute or differential position. The distance from the emitter to the target is kind of like a common-mode distance, while the difference in distance as the skin vibrates is like a differential mode. Very different scale.
They measure the differential mode, but, as to how they handle the phase disambiguation question… well, that’s part of their secret sauce, as it turns out. So my answer is… “I don’t know.”
If the target is moving, then there will be a subtle Doppler-light shift in the frequency – this provides the velocity information. This means that, with continuous lasing, you get both measurements at the same time without doing time-of-flight (which requires pulsed lasing) and without waiting for two position measurements and calculations to get speed.
So that’s how a single laser can detect its return. But… here we have an array of lasers. How the heck does each laser know which light belongs to it? It’s not like it can write its name on the light’s underwear…
And here we can thank physical variation – a source of trouble in so many other applications. It turns out that the self-mixing effect works only for light that resembles the outgoing light very closely. So closely that it’s practically impossible (or highly unlikely) that another laser would have characteristics that are close enough to be confusing. The physical variations are far larger than what self-mixing can handle.
In other words, the light from other lasers may enter a particular laser, but it’s not going to do the self-mixing thing, and so it’s effectively rejected. In the same way that penguin parents can recognize their own young out of a group of seemingly identical chicks, so each laser can recognize its own light, to the exclusion of other light. Heartwarming…
VocalZoom can also use their technology for biometrics – verifying, for example, that someone is who they say they are. Exactly how that works might be different – comparing voice signatures against a cloud reference, for example. They have some partners interested in that as well.
Voice everywhere
Finally, we move up the abstraction stack in a conversation with NXP, who had a number of related announcements at CES this year. They’re more about stoking ecosystems that, today, rely on an extra device like an Amazon Echo to handle the voice control. Why have a separate device if you can embed voice into multiple other devices? Perhaps you’re doing laundry and realize that you forgot to turn on the coffee pot: issue the command to the washing machine, which will forward it through the network to the coffee pot.
The problem here is that there are multiple ecosystems coming into play, each of which wants to rule the world. Google has one approach, Amazon another, Apply yet another. Not only are the low-level interface details likely to be different between these universes, but even some fundamental voice expectations differ.
Amazon likes it when a voice device cleans up the audio before sending it upstream. The technologies we’ve looked at above play into this. Google, on the other hand, thinks it can do a better job cleaning the audio, so it would prefer the full raw stream. The better job Kopin and VocalZoom and others can do, the less this might matter. But there’s one more reason for this: combined speaker/microphones.
The Echo and its ilk aren’t just microphones; they’re speakers as well, and, apparently, there’s an expectation that they will be your primary speakers. Part of the reason for feeding the raw audio is that Google knows what audio it’s playing – because it’s streaming it out through the speaker, and the microphone is picking it back up. So it’s easier to subtract that signal to get a cleaner version of you yelling above the music.
Of course, this breaks down if you have the temerity to use other speakers (like old-fashioned high-quality speakers); that audio then becomes part of the rest of the nameless audio background from which the voice signal must be extracted.
NXP’s sales play is processors – or modules with processors – for home goods OEMs, but they consult with their customers to figure out how to fit into as many ecosystems as possible with the fewest possible stocking numbers. That might mean adding code to an existing processor that has sufficient headroom; it might mean upgrading to a larger processor; it might mean adding a processor (or a module).
Their goal is to make it easier for OEMs, who, in general, have no clue about this technology – and don’t really want to have to become experts in it. If an additional module will solve their problem, then do that, put a bow on it (or, if in Portland, a bird), and ship it.
More info:


Do these voice recognition developments change how you think about voice as an interface?