


For large-scale systems integration, our approach to building software needs a fundamental rethink. We are imposing on machines our human-scale communication methods instead of seeking to enable machines to freely converse. The intent is straightforward: to reduce integration costs by predefining interfaces, providing backward compatibility and forward-capable integration.
When building large-scale systems we focus on how to connect the systems together instead of how they communicate. We push the knowledge of what to communicate into the code blocks that engage with each other and we spend a lot of time ‘simplifying’ communication into a syntactic bit stream, defined in a human understandable interface communication document (ICD) that embodies the real knowledge of what the bit stream is all about. When two communicating entities need to know, before a conversation starts, what the range of potential conversations could be, we have limited the potential of the two entities to serve the wider systems operational objectives, or indeed their evolutionary potential. This is what we are doing with our current software development practices: selecting protocols and defining interfaces, thereby pre-determining machine conversations that can occur. When the number of communicating entities becomes thousands, millions, or as in the Internet of Things (IoT), billions, we spend a lot of time building systems that have constrained purpose and potential! Instead, we need to build systems capable of engaging in conversations – communications that may eventually go beyond the delimited functions of the first deployment objectives.
Systems of systems have three real-world interaction points: sensors to view the operational world, actuators to enact upon the world, and the means to express, and often visualize, what the sensors and actuators are doing, have done, or are currently set up to do (the human interface aspect of actuation/sensor integration). The rest of the system-of-systems function is focused upon decision-making based on these three system input/outputs. Most of the time we start our systems design from the point of view of the human (the system interface), sort of top down. We force upon the system of systems a human-centric view of the connected world of actuators and sensors so that we can ensure the interface is human-understandable, whereas what we really need to do is think like machines – in effect bottom up – so that actuators and sensors can work together, and, when needed, their activities can be reflected to the human interface, where control can be enacted.
What machines need is their own language, an ability to understand communication, so that the mere receipt of a communication imparts all the knowledge needed to make informed decisions on what to do next. The language of machines is data – and our archaic approach of dumbing it down to a syntactic representation forces all semantic context to be placed in code. Instead, by placing communication semantics into the data and its documentation, we can massively simplify the scalability challenge of communicating systems. By defining semantics of system/software communication in the data and not in the syntax of the messages and in every communicating entity, we can manage complexity. We avoid the issues of subtle misinterpretations of software engineers trying to set their interpretation of the interface communication document into their unique code block. Misinterpretations can lie there for years until an untested event sequence exposes problems, as illustrated in Figure 1.
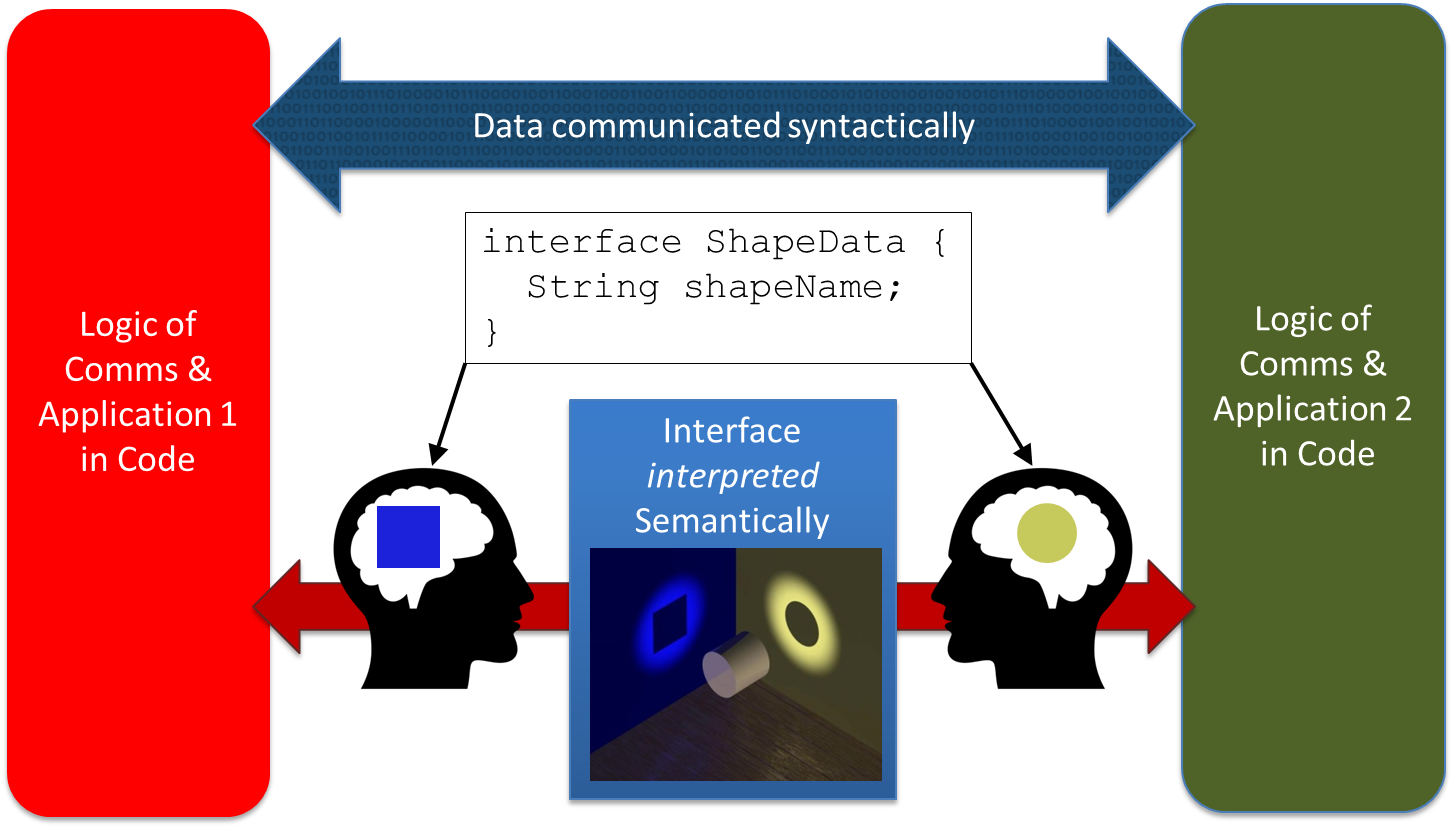
Fig 1. The problem of coding semantics in communication
By focusing on resolving the communication semantics, we can build inherently interoperable systems and sub-systems, ready to be re-used in expanded contexts or new roles. We fully decouple every communicating element from every other element and thereby clarify the decision-making activity of the code block or sub-system. Only by doing this can we scale systems of systems like the IoT to billions of devices that can effectively utilize each other’s resources.
A Highly Scalable Method to Build Communicating Systems
By leveraging the power of existing data model standards, it is possible to document data so rigorously that a computer can ‘understand’ it. This process does not rely on sophisticated, next-generation, artificial intelligence algorithms; just basic mathematics.
Using the techniques described herein, it is possible to reduce the interface and data integration process of communicating systems/software to an exercise in formal expression. This is not theory: the process we outline here has been used to build safety-critical flight management software and unmanned vehicle control systems, the most rigorous of systems of systems. But the techniques developed can be applied to any system of systems to massively simplify systems integration while increasing robustness and ability to scale.
Currently, integration is accomplished by commonality: human-inspired mediation and collaboration to create exchange patterns and structures for systems-of-systems integration. This is laborious and time consuming. What are the integrators really actually trying to accomplish? The human system architects are ‘mediating’ the interfaces. It isn’t that mediation shouldn’t occur, it is just a question of where and when in the process it should occur. At the moment, it happens many times between many people, the more so as the system scales. We need machine-defined mediation, created once and shared universally; this is the ‘language’ communicating compute elements should use.
Computer languages allow developers to clearly document very complex ideas in a machine-usable manner. Once written, these complex structures can be interpreted by any computer equipped with the appropriate tooling (i.e. compiler). Once compiled (i.e. syntax is validated and transformed), the product of the “documentation” (source code) can be moved from machine-to-machine and used again. A machine-usable replacement of the ICD enables automation of the integration process in a similar manner to the compiler process. With a rigorously documented message specifying all aspects of its attributes, including semantics, it becomes possible to match attribute to attribute across representation standards. And, with all logical aspects of the message documented (e.g. units, frame of reference), it is possible to generate transforms so the data can be directly compared. We thus create the language of machines to ‘talk’ to each other, much as humans can talk even if they have never met before. Also, the bulk of effort to document semantics and details about how the data is used can be resolved by machine, removing human error and the time consumption of manual group reviews. The process of aligning interfaces is reduced to a mathematical agreement that can be built upon as the system(s) grow.
Defining the language of machines is not terribly difficult, but it does require some advance preparation (i.e. a data model) along with an understanding of the subject matter. The ‘grammatical’ rules remain the same; the application of the rules to a domain of knowledge will extend the data model.
Machines do not initiate conversations; the demands of the function developed by a programmer initiate a request to exchange, share, or operate on data and thereby drive a system state change. We create machine conversations via messages (or service interfaces), but messages and service expressions are just a means to request or offer an operation on data or an exchange of data, the results of which may define a system state change. So the important part of the message definition is the data, not the name of the function or service calling the message. Before a message or service data attribute can be documented, it is necessary to have content and structure that can be used to document the attribute’s syntax and semantics. Therefore, the first requirement is to have a data model. The data model must contain the definition for every concept used in the message set. This includes a definition for every unit, every reference frame, every measurement, every entity, and even every attribute.
This may seem like a cost prohibitive task. It would take a tremendous amount of resources (in both time and cost) to capture that volume of semantic data in order to document all domains of knowledge. Yet we do this every time we develop or procure or integrate a new system, whether it’s a flight safety system or an IT warehouse management system. Worse, we re-invent the communication system every time, making it proprietary to the system integrator so only they can extend it!
What if the data model for communicating systems for a specific domain of knowledge were created once and then shared globally? This is what the US DoD has done. The cost was $20m ONCE, to create the method for a semantic communication data model plus the instantiation of the semantic data for flight systems and UAV control. The model is now PUBLIC (see file UCS-SPEC-MODEL Version 3.4.eap). There are other communities working to do the same for their domains. There is investment needed to understand how to create the semantic data model compliant to the method, but this IP is accessible to all to use, such that resultant data models can be added to any system using the communication method to add new domains of knowledge and thereby new system capabilities.
How to start building a semantic data model
We first need to focus on the type of semantics we wish to capture. That focus is not on the semantics of decision-making within an application, but rather on the semantics of how to express the objective of interfacing between two communicating systems. So the formalization of the Interface is a key concept to grasp. The Interface is an expression of the data and service needs between communicating elements. It is not the message used in communication – in fact, if the resultant entity model looks like a messaging model, then we have not reached the full potential in providing a conceptual abstraction of the Interface.
So where do we start to define the Interface? We can actually start in two ways. If we have an existing system, we can decompose the message model and the data operators, because they represent the aggregate programmers’ view of the system communication needs. From this view, we can start to model the data-in-motion between systems and identify the atomic elements that can represent any interface between systems, and thereby define the entities that the system needs to understand and the relationships between them. Consider this as creating the data dictionary of our system. An alternate, and arguably superior, approach is to have a domain expert work with a data modeler. The domain expert will describe all the views of system data and all their potential interpretations (contexts of use). The data modeler will then create the entities and define the relationships between entities that can exist in any system that has a discourse contextual to this domain of knowledge. Both approaches can be informed if an ICD already exists, as this includes a partially formalized (syntactic) human view that needs to be interpreted to a machine implementation. In the former approach we evolve a view of the interface needs by abstracting from existing messaging activities (although this will not inform a full data model that eventually needs to extend to potential use as well as actual known use), and in the latter we trust that the process of domain knowledge capture will create a flexible model to meet all interface requirements, while accepting that unforeseen use cases will arise that will inform future iterations of the data model (most likely through relationship definitions).
In both cases it’s an iterative learning process, documenting in a machine-readable form all the data definitions (entities) and relationships needed to manage data-in-motion and thus all interface needs of any system attempting a discourse on this subject matter.
The data model thus becomes a universally shareable asset for any system seeking to interface with any other in the context of the domain of knowledge, with only the data model needing to be updated as the ‘vocabulary’ and ‘grammar’ are expanded or improved.
So what is in the Interface Data Model?
It must define all of the basic building blocks needed to build and describe entities, their attributes, their relationships to other entities, and their logical representations in a structure that can be used in a repeatable, logical manner.
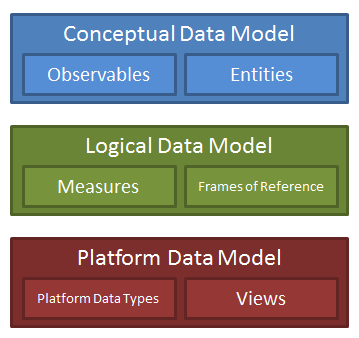
Figure 2 – Three Levels of Abstraction in a Data Model
It is critical to stop thinking about interfaces in the normal ICD syntactic expressional approach and, instead, start creating a model of the meaning of data that needs to flow through interfaces.
As shown in Figure 2, the data model is represented at three different levels of abstraction: the conceptual, the logical, and the platform. This is the normal abstraction process of data modeling. As we will see later, we will map up and down the model, or, as we prefer to think of it, create a horizontal executable mapping for machine communication.
The Platform Data Model (PDM) is the most concrete level of the data model. It needs to remove the implicit human semantic knowledge of message streams and create a machine-readable expression of what the interface needs to convey to another communicating system element.
The View is where we relate the system messages to the data model to document semantics and context. A view contains attributes that are the individual elements of each “message.” They are called “views” in order to engender thinking of “database views” rather than actual “messages.” Views are the syntactic blocks of data by which information arrives and leaves the communicating system element.
The Logical Data Model (LDM) defines measures, frames of reference and other logical aspects of describing data. This is the level of documentation that most standards handle very well. After all, in many cases, this is where much of the work seems to be, as it is non-trivial designing a mathematical transform between, for example, geographic projections. Once defined, these definitions (and their transforms) can be reused ad infinitum.
The Conceptual Data Model (CDM) is the most abstract level of the model. In addition to building blocks of the domain (i.e. the pieces needed to describe everything in this domain), the CDM contains definitions of the entities. Entities are carefully modeled to document the composition of their elements and their relationships to other entities (and even to other relationships). As the name suggests, representation of entities in the CDM are intentionally designed using abstract “concepts” rather than more concrete representations.
For example, a model of an aircraft can be constructed in the CDM. At this level, the aircraft does not have a “latitude and longitude,” it merely has a position. Why? The reference frame, units, and representation are logical constructs and are elaborated in the LDM. At the CDM, position is just a concept and can be compared to other, equivalent concepts. Therein lies the magic of machine level semantic communication. Historically, when one message refers to an aircraft’s position in earth-centered-earth-fixed coordinates (X, Y, Z), the data does not resemble the geodetic position (latitude, longitude, altitude) in another message. Conceptually, however, they are the same thing. The CDM provides the ability to compare concepts based on what they actually represent. This information is used to form the context. Thus, it is absolutely necessary to have a data model that has been well-informed by domain experts.
Putting all of this together, we see how the three levels of abstraction work together to facilitate systems-of-systems integration. Starting with the position interface to the left of Figure 3, we trace the low-level, concrete representation of the PDM to the well-formed definition we ultimately need in the LDM. The approach described herein takes things a step further by then tracing each representation from the LDM to the CDM where we can find other representations that reference the same entity and attribute. Now that we have discovered that both of the low-level position interfaces are talking about the same concept, the LDM can be used to inform a runtime transformation from one form of the data to the other (mediation).
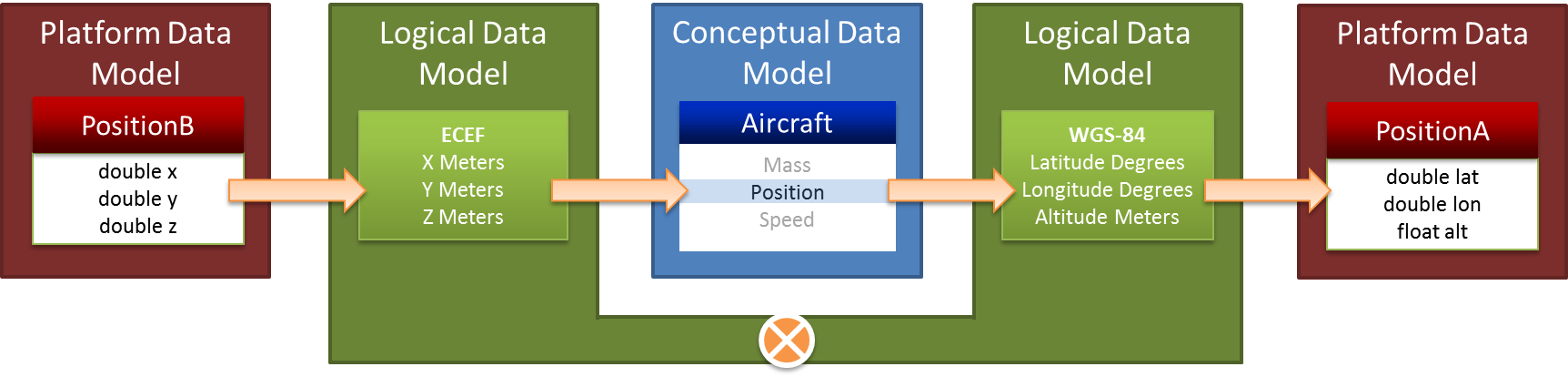
Figure 3 – Example Runtime Interpretation of the Interface Model
Imagining the future of Integration
Imagine a data-model-driven infrastructure in which system integration can be performed by loading a documentation file. This will practically eliminate the need for costly, time intensive integrations. Instead of wrestling with precise wording in an ICD (subject to interpretation), systems engineers can spend a comparatively small amount of time creating machine-understandable documentation of their interfaces.
The process of documentation effectively becomes the integration!
Architects will either pull in the interface data models they need (creating licensing opportunities) or model them for new domains of knowledge. Much as early compilers competed for the quality and performance of the code they generated, companies will spring up to compete on the quality of their interface models and the veracity of their underlying domain-centric data models. Open standards will evolve (in fact are evolving) to define extensible data architectures, thus ensuring that we don’t repeat the proprietary integration problems of the past and create artificial barriers to systems interoperability.
Systems that are built to inherently interoperate will open up new business models based upon exploitation of emergent system properties that can be readily integrated. Engineers will be able to focus on developing new system capabilities because they can spend more time on innovating. Code re-use will become even more prevalent and create new markets for licensed sub-system software, enabling domain-specific “app store” development. Purchasers will be able to define how the supply chain will integrate, thus breaking down the proprietary supply-chain lock-in currently enforced through effectively closed interfaces.
Finally, and perhaps most importantly, systems will be able to naturally scale far beyond the human-scale levels of understanding that we artificially build into our software architectures today. The IoT could become a reality instead of the IoS (Internet of Silos) currently evolving from protocol- and API-standards-based methods of enabling system integration.
Conclusion
A data model isn’t a luxury; it is a necessity. In fact, it has always been a necessity. Engineers integrating systems have routinely answered the questions of structure, meaning, and behavior. This information isn’t new. The need for the information isn’t new.
What is new is how this information can be documented and leveraged to manage the scale, flexibility and complexity of integration. This paper has introduced both a data architecture and a methodology that a tool can exploit to document the data – syntax and semantics.
It is important to realize that scalability issues aren’t new. In the world of data-at-rest and big-data analytics, we are leveraging contextual models and semantics to process, discover, and correlate information in new and interesting ways. However, the power of this data modeling approach has been underutilized when documenting machine communication, which is at the heart of the scalability challenge of systems.
Much in the same why early database structures transformed the world of information management, these contextual models and structures for communicating machines will transform the world of systems integration. It is going to be an exciting development.
Authors:
Chris Allport, Skayl, chris@skayl.com
Gordon Hunt, Skayl, gordon@skayl.com
Geoff Revill, Market Altitude, geoff@market-altitude.com


What do you think of this IoT interop approach?